
先日ついにtidyrパッケージで縦横変換をやってみた。今までずっと覚えなきゃなと思ってて結局億劫でやってなかったんだけれど手伝いで仕方なく。
データハンドリングで,横に広がる(列数の多い)wide-formatのdataを分析に便利なlong-formatに変換するというのは,分析をやるまえのデータ整形の過程で必ず通らなければならない道。Excel上で地道にやるのもあるにはあるだろうけど,Rのtidyrを使えばすぐできるというお話。これ系の話はググればネット上にゴロゴロ記事が転がっている。なので,今回は具体的に外国語教育研究系のデータ分析ではどんなときに役に立つかなーという話です。特に無駄に変数が多い時なんかは結構役に立つと思います。

sample data
適当にこんな感じでデータが入っているとします(数値は乱数)。事前・事後・遅延事後のテストがあって,それぞれで流暢さ(fluency),正確さ(accuracy),複雑さ(complexity)の指標があるみたいな。1列目には被験者番号があって,それぞれの列名は”test.measure”という感じでドット区切りにしてあります。で,これを,「事前・事後・遅延事後」の3つのカテゴリカル変数からなる”test”列と,3つの指標(CAF)の”measure”列の2列に分解しましょうという話し。
R上に上のようなデータを読み込みます。

read.table関数で読み込んだ場合(※MacなのでちょっとWindowsと違います)
まずはパッケージの準備
install.packages(“tidyr”) #パッケージのインストール
library(tidyr) #tidyrパッケージの呼び出し
datに入っているデータフレームをまずは,変数名の列(variable)とその値(value)の列に集約します。key=変数名の列,value=値の列という引数指定です。
#%>%はパイプ演算子。以下の関数で扱うデータフレームを指定するということです
dat %>%
#-subjectでsubjectの列を除外。変換したdataをdat2に入れる
gather(key = variable,value = value,-subject) -> dat2
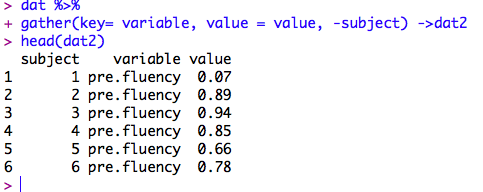
long formatのデータに変換されました
これで変数名を1列に集約できました。ただし,この列にはpre, post, delayedというテスト実施時期の情報と,fluency, accuracy, complexityという指標の情報が混ざってしまっています。これを,2列に分けます。
dat2 %>%
#colで分けたい列名,intoで分けた後の列名を指定。sepでセパレータを指定しますが,デフォルトはあらゆる非アルファベットになっているので,ドットなら指定しなくても大丈夫
separate(col = variable, into = c(‘test’, ‘measure’)) -> dat 3
さて,dat3の中身を確認してみると…

long formatのデータに変換されました
おおおおー!!!!!
というわけで,横に変数がたくさんある場合もこのtidyrのgatherとseparateを使えば簡単にlong型に変換できそうです。
参考サイト:http://meme.biology.tohoku.ac.jp/students/iwasaki/rstats/tidyr.html
なにをゆう たむらゆう
おしまい。

ピンバック: dplyrを使ってみる:long型から記述統計 | 英語教育0.2
ピンバック: [R] 初心者向け縦型変換 | 英語教育0.2