はじめに
私は何年か前から,「やることリスト」や「To Do List」ではなくて,「やったことリスト」をつけるようにしています。
ToDo(やること)リストじゃなくてDone(やったこと)リストをつけよう
2つの記事のうち下のものは10年以上も前に書かれているので,アイデアとして何か目新しいわけではありません。なんでそれやるの?みたいな話の詳細は上の2つの記事をお読みください。私はとにかく,「なにかやった」ということを日々積み重ねていってそれを可視化したい,というのが大きいです。「いや〜今日は何もできなかった」という日でも,ノートを書くために一日を振り返ってみたら,「仕事をしないぞ。休むぞ。」と決めた日以外には絶対に何かやってるんですよね。「あ,何もやってないと思ったけどなんかやってたわ。」と(自己肯定感下がらない)。「てか意外に結構やってない?」と思う日もありますし。一日にやってる仕事の数が多すぎて,こんなリスト書いてる時間がもったいないよと思っちゃう人もいると思いますけど,そういう人は別にこんなことしなくても自己肯定感下がったりしないと思うし必要のないことなので,関係のない話かなと思います。私みたいに,「ああ,私は仕事のできないダメ人間だ」という気持ち(になったりすることがある)人の参考になる可能性があるかもしれないということでこの記事を書いています。ぜひ試してみてください。
さて,この記事では,Obisidanを使って「やったことリスト」を実現する方法を紹介します。
以前はEvernoteでやっていた
リストをObsidianに移行する前は,Evernoteに一つの「やったことリスト」というノートを作って,そこに毎日日付の見出しを作ってからチェックボックスで消していく(あえてチェックボックスにするのが個人的には重要)というようにしていました。このノートはホーム画面にピン留めしておいて,Evernoteを開けば常に見れるようにしていたというわけです。
Evernoteは値上げをどんどんしていて,Evernote離れしている人も増えていますが,私個人としてはWebクリッパー(この用途では10年以上使っています)や紙関係でスキャンしたものの保存先として多用しているので,利用を辞めることはおそらく今後もないと思います。ただ,研究関係のメモをObsidianに移行してからは,Evernoteを開く機会自体が結構減ったんですよね。結果として,Evernoteを開くのが面倒だからリストを作るのも面倒で,さらには毎日日付を自分で書くのも面倒だなと思い始めてしまったのです。
日付書くの面倒問題以外でも,リストにちょっとしたメモを残したりできたら便利だなと思っていました。次はこういうふうにやり方を変えようとか,これの続きを次にやるときはこっからスタートだよとか。そういう余白みたいなのがないんですよね。一つのノートだと。となると,毎日のノートが独立していたほうがいいんです。最近Evernoteでもデイリーノートが作れるのを知ったので,Evernoteでも解消できるかもしれませんが,研究関係のものが常に目に入るようにするためにもObsidianは常時開くようになっていたので,Obsidian上でやったことリストができないかなと思い,実際にやってみたというわけです。
自分が理想としていたリストの作り方
いろんなやり方があると思いますが,私が思い描いていたのは次のような仕組みです。
ワンクリックでデイリーノートを作れる
デイリーノートにはテンプレとしてタスクリストがすでに記入されている
毎日のデイリーノートが「やったことリスト」という名前の別のノートに自動的にリンクされる(やったことリストからデイリーノートにジャンプできる)
リンクされるのは「リスト部分」だけで,見出しが日付,その下にリスト,という見え方になる
新しいリストは常に上に追加される
おそらく,1のところはコアプラグインの起動時にデイリーノートを開くという設定をONにすれば,クリックすらせずにデイリーノートが作れると思います。ただし,私の場合は毎日の日記というよりも「仕事」メインなので,仕事をしない日にはデイリーノートを作る必要がありません。むしろそれで作ってしまうと,デイリーノートがあるのに何もやっていない日が逆に可視化されてしまって本来の目的と逆方向にいってしまうのでよくありません。そういうわけで,ワンクリックする手間を設けています。
必要なプラグイン
多分最小限でこの2つで可能なはずです。まずはプラグインをインストールしましょう。話はそれからです。
ちなみに,私はなぜかコアプラグインの”デイリーノート”ではなく,”Periodic Notes “というコミュニティプラグインを使っています。なんでそうしたのかはもはや忘れました。WeeklyとかMonthlyとかのノートも作れるので汎用性が高いからかもしれません(まだ毎週,毎月とかでノート作って書いたりしてないですけど)。あ,”Calendar “プラグインとの統合があるからかもしれませんね。カレンダービューで日付をクリックするとその日のデイリーノートに飛んでいけるみたいな。もしかしたらコアプラグインのデイリーノートでもできるのかもしれませんけど。まあそれは今回のメインの部分とはあまり関係ないので割愛します。
それから,”Dataview “これが肝です。これがあることで,日々のデイリーノートを「やったことリスト」に蓄積していくことができます。使い方はめちゃくちゃ汎用性が高くて難しいので,私はChatGPTに聞きながら使いました(もっというと,「Obsidianで,デイリーノートが自動で生成され,そこに作られたタスクビューが自動的に別のノートに蓄積されていくっていう仕組みを作りたいです。」ってChatGPTに質問して教えてもらいながらトライ・アンド・エラーを繰り返して最終的に自分が欲しかった形にたどり着きました)。
余談ですが,ChatGPTに教えてもらったときに,Tasks というプラグインをいれるように言われましたが,実際にはこのプラグイン入れなくてもこの目的で利用する分には何ら問題ありません(このプラグイン自体は便利だと思いますが)。私は締切があるようなタスク管理にはMicrosoftのToDoリストを使っているので。
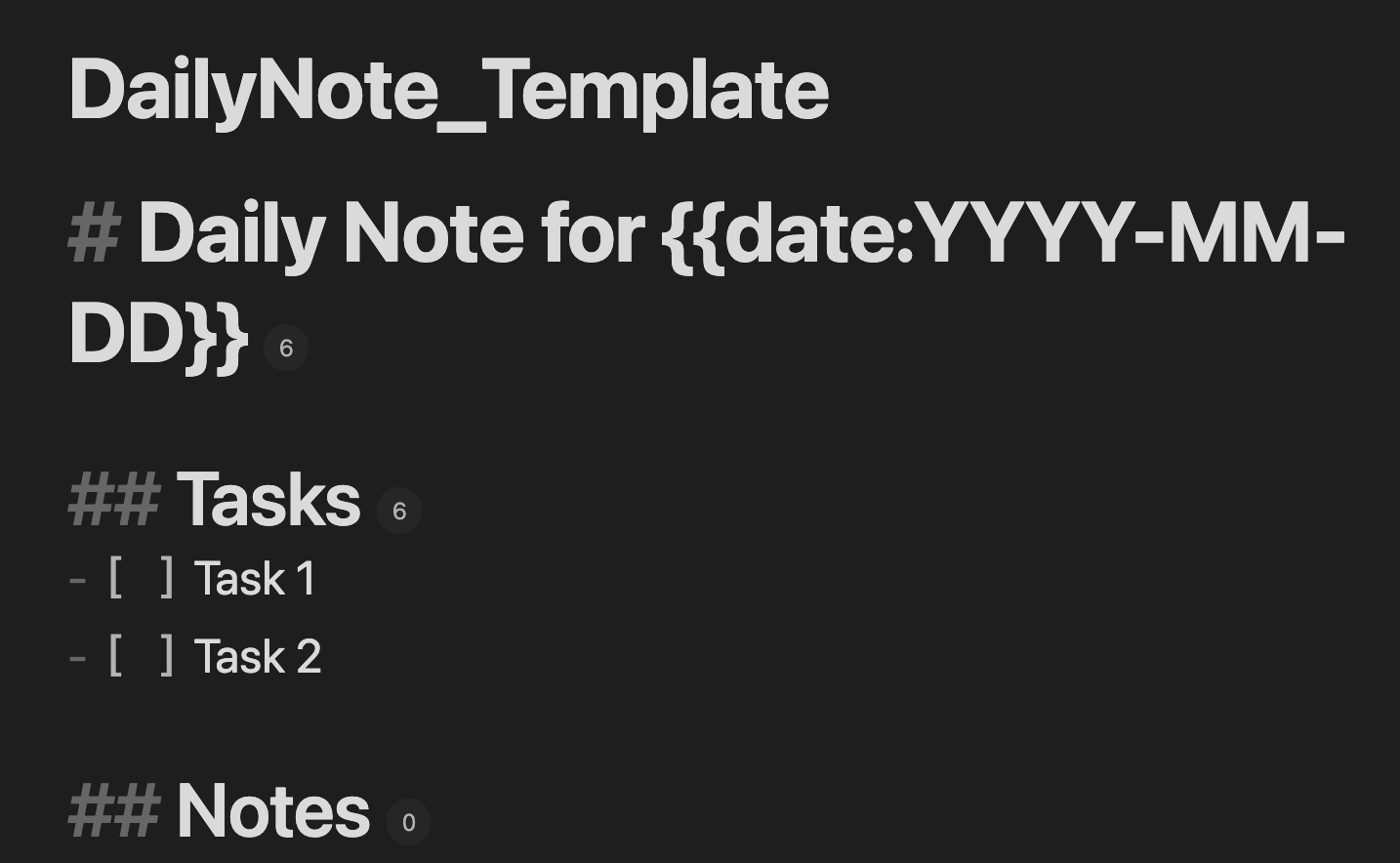
手順1. テンプレファイルを作る
テンプレファイルを作って,保管庫に置いておきましょう。私は保管庫直下にDailyNote_Template.mdというファイル名で下記画像のようなテンプレファイルを作りました。そして,新しいデイリーノートは”DailyNote”というサブフォルダ内に生成されるようになっています。
同じ名前のファイルがあればそのファイルが開かれるようになっているので,同じ日に複数のファイルを生成してしまうということはありません。やったことはTasksのところに記入していって,メモ的なことはNotesに書くという感じになります。
手順2
デイリーノートが生成されるサブフォルダ内に,「やったことリスト」という名前のノートを作ります(もちろん名前はなんでもいい)。そのノート内に次のように記入してください。”DailyNote”というのはノートを引っ張ってくるフォルダの名前ですので,ご自身の環境に合わせてそこは書き換えてください。
```dataviewjs // ページごとのタスクを格納するための空のオブジェクトを初期化
let tasksByPage = {};
// "DailyNote" フォルダ内のすべてのページを取得し、作成時間の降順でソート
let pages = dv.pages('"DailyNote"')
.sort(p => p.file.ctime, 'desc');
// 各ページを繰り返し処理し、タスクを抽出
for (let page of pages) {
let tasks = page.file.tasks;
// ページにタスクが含まれている場合、未完了タスクと完了タスクに分類
if (tasks?.length > 0) {
tasksByPage[page.file.path] = {
page: page,
incompleteTasks: tasks.where(t => !t.completed),
completedTasks: tasks.where(t => t.completed)
};
}
}
// tasksByPage オブジェクトの各エントリを繰り返し処理してタスクを表示
for (let path in tasksByPage) {
let { page, incompleteTasks, completedTasks } = tasksByPage[path];
// 未完了タスクがある場合、それを表示
if (incompleteTasks.length > 0) {
dv.taskList(incompleteTasks, { checked: false });
}
// 完了タスクがある場合、それを表示
if (completedTasks.length > 0) {
dv.taskList(completedTasks, { checked: true });
}
}
// タスクが見つからなかった場合、メッセージを表示
if (Object.keys(tasksByPage).length === 0) {
dv.paragraph("No tasks found in the daily notes.");
}```色々ChatGPTとあれこれやり取りした結果,DataviewJSというのを使うことになりました(プラグインの設定でDataviewJSが使えるようにしてください)。ぶっちゃけ,このコードに実は余剰な部分とかもあるのかもしれませんが,これで機能しているのでとりあえずいいとしています。「やったことリスト」の出力は下記画像のような見た目になります。
私が結構難儀したのは,最新のノートが上に来るように並び替えることと,見出しをファイル名だけにすることです。見出しにファイル名と日付がダブって入ってしまったりして,かなり何回もChatGPTとやり取りした記憶があります。
ちなみに,完了マークと日付が入っているのと入っていないのがありますが,完了マークと日付が入るのはTasksプラグインの仕様です。このプラグインを使うと予測変換の入力がうまくいかないというのと,項目だけ立ててチェックを忘れてしまったときに,本当はその日のうちにやったのに次の日に終わったようにチェックが入ってしまうというのがあって,他のノートのタスクリストとかでもこのプラグインなくても問題ないよな?とさっき確かめたら問題なさそうだったのでアンインストールした結果,今日の分だけ見え方が変わっています。
もうひとつちなみに,22日の次からノートがスカスカになっているのは,コロナに罹患して仕事どころではなかったからですw
何を「やったこと」に含めるか
私個人的には,研究に限らず仕事の範疇に含まれるものは結構細かいものでも含めています。メール返信とかは一度の返信で済むものだったのでそういう書き方していますが,もし何往復もするようなものだったら,「XXXについてメールでやりとり」というような書き方にしています。論文も,「ただ書いた」だけだとどんくらい書いたとかどこを書いたとかがわからないので,できるだけ具体的にするようにしています。大きなタスクの中にサブタスクがある場合は22日の例のようにインデントしています(実際には論文は書き終わっていないけれども親タスクのところもチェックするのがポイント)。論文とか研究とかはまた別にObsidianの中にまとめのTodoリストがあって,ある研究や論文に固有のノートの中のリストが#ToDo/Researchで拾ってこれるようにしていたりします。そことデイリーノートを連携できていたりはまだしないので,重複した内容をデイリーノートに書くこともあるといえばあります。ただ,そもそもこの「やったことリスト」を作って蓄積していく目的というのは,「なんかやったぞ」もっというと,「何もやってなくないぞ」というのを可視化する目的なので,厳密に「やらないといけないこと」(ToDoリスト)と一致していなくてよいと思っています。むしろ,そういうToDoリストにもぶっちゃけのぼりもしないような細々としたタスクをも 可視化するののが目的なんです。
おわりに
この記事では,「やったことリスト」をObisidanのデイリーノートとDataviewを使って蓄積・可視化していくということを書きました。ChatGPTに聞けば,もっと多分いろんなカスタマイズできるんじゃないかと思いますので,詳しいことは私に聞かないでください。
なにをゆう たむらゆう。
おしまい。