フィードバックをもらいたいライティングプロダクトを入力して,緑のボタンを押すと,下のような画面が現れます。今回は,私が修士課程にいたときの授業の1つで,”Explain Bourdieu’s three kinds of capital. Give some examples and tell how they are related.”というお題で書いた短い文章を使ってみました(他にパッと使えるものが思い浮かばなかったので)。
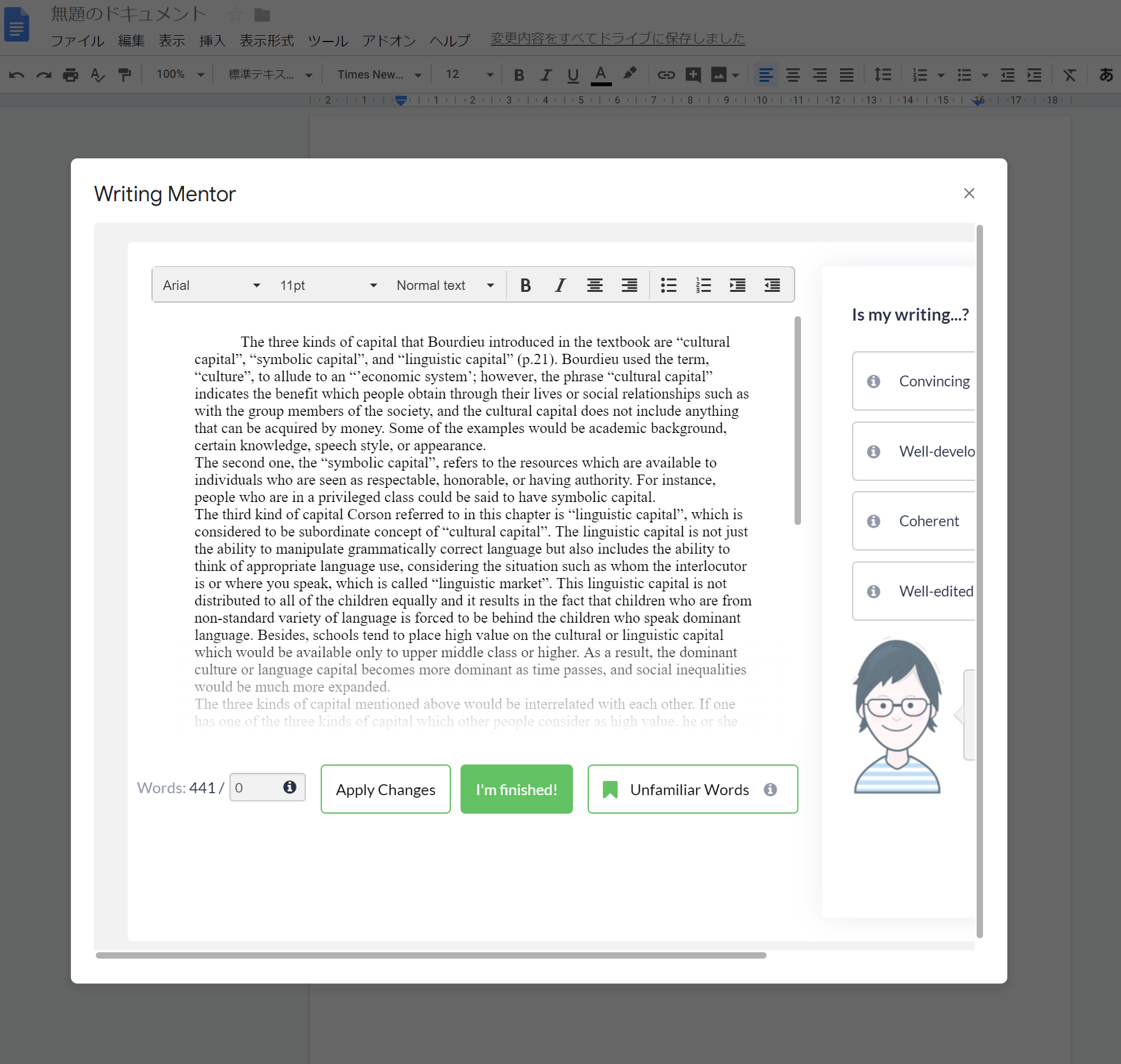
この下位分類として,Flow of ideas, Transition Terms, Long Sentences, Title&Section Headers, Pronoun useの5つがあります。Title&Sectiobn Headersはヘッダー入れようねということなので,長めのペーパーを意識したフィードバックかなと思います。今回は短い文章なので,それ以外の4つを見ていきます。
Flow of Ideasは,前のWell-developedとほぼ同様ですが,トピックが複数ある場合に有効なようです。今回は短めだったからかメイントピックは1つと認識されましたが,メイントピックが複数ある場合はそれに関連したキーワードのみを表示することが可能なので,複数のメイントピックがごちゃごちゃになっていないのかを確認することができるのだと思います。つまり,メイントピック1を書いている部分にメイントピック2のtopic keywordsが混ざっちゃってるよ!というようなことが視覚的にチェックできるということなのでしょう。このあたりは未確認なので,もっと長い文章で試してみる必要がありそうです。
Long Sentencesは文字通り一文が長いものをハイライトしてくれて,2文以上に分割したら?と言ってくれます。これは一文に含まれる節の数で判断しているようですが,単純にそれだけではないようで,割と単純そうに見えるものでもハイライトされたり,逆にthat節の中に関係節が埋め込まれているというようなものはハイライトされなかったりしています。
Pronoun useは,文章中の代名詞をすべてハイライト表示し,
Do pronouns in your assignment refer to one clear noun referent? Read aloud the sentences containing pronouns to make sure that the references are clear to you!
最後に,文法などの誤りへのフィードバックです。下位分類として,Errors in Grammar, Usage & Mechanics, Claim verbs, Word choice, Contractionsがあります。
Errors in Grammar, Usage & Mechanicsは,文法の誤り,綴りの誤りなどを訂正してくれます。冠詞や数の一致はしっかり拾ってくれますが,統語的な誤りについては難しいようです。例えば,次の文(もとの文から関係詞を削除したもの)は誤りとして検出されませんでした。
it is obvious that children (who) have cultural and linguistic capital which is considered to be valuablewouldbe able to achieve high social status, symbolic capital.
私の研究室の机は,デフォルトでおいてあるオフィスワーク用のデスクで,左右に引き出しがついているものです。横幅がそれなりにあるので,42.5インチのモニタを置いても,その横にUSBハブ,HDD,AirMac Time Capsuleを置くくらいのスペースはあります。逆側には23インチモニタ用のモニタアームもつけてます。
Ed. by Ahmadian, Mohammad / García Mayo, María del Pilar
この本全体については,Cognitive-Interactionist, Sociocultural Theory, Complexity Theory, Pedagogic and Educationalという4つのperspectivesからなる12章の本で,個人的には通読するよりも気になった章だけつまみ食いするという読み方がいいかなと思います。正直言ってあまりおもしろくない(質があまり高くない)チャプターも結構ありますので。
第7章がおすすめ
この本の第7章は,Martin Bygateが書いた”Dynamic Systems Theory and the Issue of Predictability in Task-Based Language: Some Implications for Research Practice in TBLT”という論文です。タイトルにDynamic Systemsと書いてありますが,そこまでDSTを推しているということではなく,「タスクってさ,何かやらせてみてもどんなことが起こるかわからないしリアクティブに教えるのがいいっていうけどやっぱそういうの不安だもん」みたいな言説について,predictabilityが一応ありますよっていうことを言うための理論的基盤としてDSTを持ってきているという印象です。それをベースにして,ケーススタディ的にデータを見てみるというようなのがこの論文の流れです。
A phase was defined in terms of the pragmatic coherence of a stretch of discourse which while not in itself achieving the overall task goal, likely contributed to achieving a useful enabling sub-goal. For instance, descriptions of the individual pictures in random order would contribute to the sub-goal of sharing information about the pictures, but would not themselves achieve the overall goal of sorting out the sequence and telling the story (even if by chance the students did actually provide the descriptions in the exact sequence of the narrative). Similarly, discourse during which students exchanged information about what they thought was going on in their respective pictures could not be interpreted as ‘telling the story’ either. Where students spent time suggesting potential sequencing of the pictures (still without seeing them), possibly accompanied by brief justifications, this kind of talk too contributes to a potentially useful subgoal, but still does not constitute the ‘telling of the story’. Hence the macro-purposes of the different discourse phases were inferred in relation to the pragmatic criterion: what are the speakers jointly trying to do at this point? Identification of phases enabled an assessment of the trajectories that the groups followed (p.155).
上の引用中では,”(sorting out the sequence and) telling a story”というのがタスクの最終的なゴールで,そこに到達するために有効なやりとりや言語行為をphaseとしています。複数コマ漫画の並び替えならば,まずは個々人の持っている写真を描写することからスタートすると予測されるので,それが一つのphaseになるというわけです。そして,自分の写真とグループメンバーの写真についての情報を全員が持った状態で,それぞれの写真に描かれている情報の違いを見つけることになります。そして,「いったいどんなストーリーなのだろうか」という話をしながら前後関係を特定していくことになると予想されます。これらの段階もすべてphaseであると。そして学習者はこういった複数のphaseを経て,最終的なゴールに辿り着くというわけです。
the language for expressing impressions, inferences and approximations; the language of description and for identifying similarities and differences; the language for expressing motivations and consequences; the language for sequencing; and the language used for checking understandings (p. 160).
it is important to note that the phases do not imply total predictability. For one thing, the phases sometimes occur more than once in a single transcript, with students going backwards and forwards between, say, finding the gist and trying out a sequence (p.160).
また,「たとえsub goalsが明示されなくとも学習者たちは多かれ少なかれphaseを経てゴールに到達する(=予測可能性がある)」ということを言っています。つまり,phaseは与えられなくてもある意味でタスク達成に向かう試行錯誤の中で創発するということですね。それを手助けしてやることはあったとしても,最初からこの通りにやりなさいというのはtoo much interventionかなと個人的には思います。「正しい手順」や「理想的な手順」のようなものがあると学習者が思ってしまい,それに囚われすぎてしまう可能性があるからです。例えば,2. comparisonからいきなり4. sequencingに入ることも十分にありえることです。「まって,私の絵ではりんごは食べかけで,Aくんの絵ではりんごは丸々1つあるから,きっと私の絵はAくんの絵よりあとにくると思う」のような発話が起こることは歓迎されるべきで,「まって順番考えるより先にストーリーをつかもうよ」となってしまっては学習者の自由な発想が抑制されてしまうかもしれません。よって,sub goalを与えてそれに沿ってタスクを行わせることは有効な手立てとは言えません。
sub goalという考えは,事後のフィードバックにとっても有効かもしれません。もしも,時間内にうまく課題を達成できなかったグループがあったとして,そのタスクにおいてsub goalsをいくつ達成できたかという点で見てみると彼らの課題が見つかるかもしれないからです。Bygateの示したデータでは,すべてのグループがタスクを達成したため,「phaseとタスク達成の関係」は完全には明らかになっていません。タスクを達成できなかったグループがいたとして,そのグループがもし仮にすべてのphaseを通過したのにできなかったとすれば,phaseはirrelevantということになります。しかしもしかすると,どこかでつまずいたことが原因でタスクを達成できなかったという学習者がいるかもしれません。絵の微細な点について,描写しなかった(またはできなかった)けれども実はその点が他の絵との違いで,その情報を全員で共有していればタスクが達成できたかもしれないということはありえます。別のケースで,sequencingでつまづいて終了してしまったとします。このときに,follow, precede, come before, come after, first, next, then, before, afterのような前後関係を表す表現がうまく使えなかったので並び替えができなったということがわかれば,その学習者たちに必要なのはこうした前後関係を表現する言語リソースが足りていないということになり,そこがteaching pointになるでしょう。言語面については,varietyが大きすぎて一貫性は見られなかったというのがBygateの結論でしたが,具体的な場面での話に限定すれば指導のヒントにはなるでしょう。
もう秋学期も終わりに近づいていますが,半期をOneDriveとMS Word Onlineを使ったライティング活動でやってきて思うことは,ドラフト作りに対するエフォートが減ったかなということです。もちろん,大学1年生の春学期と秋学期を比べれば,出席率や課題の提出率など,割と一般的にどちらも下がると言っていいくらい普遍的な現象のような気もするので,私の授業スタイル変更が影響を与えただけとは言い切れません。ただ,紙の場合は「授業中になんとか終わらせて出す」という感じで一生懸命やっていた学生も,オンラインだと「今終わらなくても宿題でいいや」,「スマホでいつでもできるし」のようになっているのかなと思うことがよくあります。そして,結局後回しになっても,授業期間以外にファイルを開いて書き込むということをやっている学生の割合が低く,「いつでもできる」と思うからこそ逆に取り組みづらくなってしまっているかもしれないなと思っています。一応こちらからも声掛けをするようにはしているのですが,この点についてはなかなか解決策が見つかっていないので,来年度春学期以降の課題かなと思っています。
おわりに
紙には紙の良さもあって,オンラインにはオンラインの良さもあるとはいえ,今回は紙,今回はオンラインのように分けて使うのも混乱の原因になるので,オンラインの良さを活かした上で,欠点を補いながら授業を作っていければいいなと私自身は思っています。やはり,授業外で添削にかかる時間は膨大なので,それを少しでも減らして授業の中でフィードバックを多く出すというのがオンラインでライティングをすることの一番大きな利点でしょう。この利点はライティングを教える側としてのsustainabilityとかquality of lifeにも関わるので,より良い形でオンラインフィードバックを活用した授業を模索していきたいと思っています。
さて,「比較がよくできた」とはどういうことなのでしょう。それは,「何と何を,どういった観点から切り取って比較したものなのかがわかりやすい」というようなことなのか,それとも,「In contrast, On the other hand, whereasといった比較を導入する表現を使って書けていた」ということなのでしょうか。ここまで具体的に言語化できれば,「自分が真似する」ときに何を真似すればよいのかがより明確になってきていることがわかると思います。
a. As the mother and the father battled the child played the guitar in the room.
b. As the parents battled the child played the guitar in the room.
c. As the mother and the father left the child played the guitar in the room.
d. As the parents left the child played the guitar in the room.
battleのような相互作用動詞が目的語を取らないという解釈にいたるためには,主語が複数である必要があります。その時には相互作用動詞の後ろの名詞句は主節の主語として解釈され,ガーデンパスを回避できるということです。4条件作っているのは,(a) A and B(conjoined NP)とthe parentsのようなplural definite descriptionを比較したこと,(b) 動詞のバイアスの影響ではないことを示すために自動詞と他動詞の両方が解釈として可能な動詞の条件も用意し,その場合にはガーデンパスを回避することができないことを示す必要がある,という2点が理由です。
まず,Bilingualism: Language and Cognitionに出しました。そこでは,査読に回る前に,「母語話者と比較してないからだめ」という理由で突っぱねられましたが,「母語話者のデータがなくともこの実験の結果のみで十分に価値がある」という長めのメールを送り,いくつかの修正条件を提示されたのでその修正をし,最初の投稿から1ヶ月後くらいに再投稿しました。査読に周り,再投稿時点から2ヶ月たってreject通知をもらいました。とにかく,コメントの鋭さが今までに経験したことのないもので,すごくショックを感じるとともに,これをもとに修正したらもっと良くなるに違いないとも思えました。
二回目の投稿
大幅な書き直しが必要で,イントロ,バックグラウンド,ディスカッションとほぼすべて書き換えました。そして,2017年2月に今度はLinguistic Approaches to Bilingualismというところに出しました。外部査読に回るまでが1ヶ月,外部査読に回ってからは3ヶ月で結果が来たので,投稿から最初の結果がわかるまでは4ヶ月でした。そして,またrejectでした。