これは痺れた。優勝はできなかったけど,ダンクコンテストのダンクの中ではこれが個人的にはベストダンク。アイデアもそうだし技術もすごい。
All-Star Slam Dunk Contest 2016
コメントを残す

これは痺れた。優勝はできなかったけど,ダンクコンテストのダンクの中ではこれが個人的にはベストダンク。アイデアもそうだし技術もすごい。
昨日今日と風邪でダウンしていましたが(体調不良でダウンしたのは数年ぶり),明日2月12日金曜日より通常営業に戻ります。ご迷惑をおかけして申し訳ありませんでした。

厚切り和風ローストポーク。
飯というよりつまみだけれど。豚肩ロース塊り肉を安く買ったのでその半分を使った(もう半分は大根と煮物にしている)。塩胡椒を刷り込んでからフライパンで表面に焼き色をつけてオーブンでじっくりと中まで火を通して完成。ソースは大根おろしと和風ドレッシングだけど、肉が脂っこいのでポン酢かノンオイル系のドレッシングが本当はよかったかな。
居酒屋たむらのメニューに追加。
3人とも理系の人たちだからかもしれないけど,なんか自分と同じような境遇にはあまり思えなかった。にもかかわらず自分の方がたいぶのらりくらりやっていて,その上に技術も専門性もない。なんというかもっと頑張ります…
博士になっても努力が報われない「ポスドク問題」。当事者3人の姿から、その解決法を探る。

ポークソテートマトソース
「なぜ学校へ行くのか」という本を読んだ。途中までずっと積読状態になっていたのだけれど,ふと最近また本を読んでないなと思って再開した。第3章あたりから,人間の本質的な能力であり,人間らしさの根源である選択能力,選ぶ力,という話が出てくる。人間は生まれてからずっと様々な選択を繰り返していく生き物であり,選択することができるというのが人間であることであるというような事が述べられている。しかしながら,学校ではこの選ぶ力を育てることができていないのが現状ではないかというのが著者の主張である。
この主張を自分の興味関心や研究に引きつけて考えたときに,タスクのことが思い浮かんだ。別にタスクである必要はないのだけれど,新しい言語項目を教える->練習する->使う,というような手順の指導のことを考えたのだ。いわゆるPPP(Presentation-Pracice-Production)というやつ。そう,この指導過程の中には,学習者が何かを「選ぶ」という過程が全く無いではないかと考えたのだ。いや,まったくないとも言い切れないかもしれない。例えば,いわゆるfill-in-the-blank exerciseのような課題を練習セクションで行ったとすると,そのカッコに何が入るのかを「選ぶ」という作業は確かに発生するからだ。ただし,実際に言語を使う際に,あるカッコに何が入るかを「選ぶ」という作業の必要性が発生する場面があるだろうか。昨年中部地区英語教育学会にて発表した中学校教科書分のタスク性分析研究(たぶんそろそろ投稿する)のときにも散々主張したことであるのだが,「何を言うのか」を考えて,それを「どのような言語形式で表現するのか」という過程を体験することは,中学校教科書に掲載されているコミュニケーション活動を行っただけではほとんどできないと言っていい。
しかしながら,この過程を体験する事こそがまさに「選ぶ力」につながるのではないだろうか。「どのような言語形式で表現するのか」を「選ぶ」というのが,産出の際には非常に重要になってくる。そこを考える,何を選択すべきなのかに思いを巡らせることがほとんどないということの背景には様々なものがあろうだろう。著者は,テストの点数で能力を測定しそれによって序列化することを問題点として挙げ,その影響で,とにかく問題の答えを知りたがる子どもができあがっている,問題から答えに至るまでの過程をすっ飛ばして答えを暗記することを暗に助長してしまっていると述べている。
英語の授業(テスト)を考えみると,正確さの重視というものが,問題の答えだけを知りたがるという状況を作り出してしまっているのかもしれない。とにかく誤りがあれば減点されるわけなので,誤りのない表現が欲しい。なので,「なぜその言語形式なのか」はすっ飛ばしても,この表現なら間違いがないというものを持っていれば安全なのだ。
タスクを遂行することを考えてみる。タスクは文法的な正確さで評価をされず,タスクが達成されたかどうかが評価の基準となる。「正しい」か否かで評価されることがなければ,とにかく自分の伝えようとしていることが相手に伝わるかどうかという点だけに学習者は集中する事ができる。そういう状況では,自分が伝えようとしていることをどのような言語形式で表現したらいいのかを考えて選択し,まず頭に思い浮かんだ表現で伝えてみるだろう。もしその表現で伝わらなかったという場合には,ではどのような別の表現を使えば相手に伝わるのだろうかとさらに考えて選択を行う必要が生じるはずだ。
いくら練習に練習を重ねても,「何を言うべきか」と「どう伝えるべきか」という2つの選択をする機会が保障されなければ,その日に習った表現をその日に使うことはもしかするとできるようになるかもしれないが,どのような表現を使うべきかの選択が迫られるコミュニケーション(実際に起こるコミュニケーションではこれが当たり前のはず)場面では何も言えずに終わってしまうだろう。
タスクの話をすると教えることを軽視しているというような批判をよく受けるが,教えるなとは言っていない。教えてもいいから,教えたことを使うということに終始せずに,とにかく「選択する力」を養うことができる機会をもっともっと増やしませんかと言っているだけなのである。学習者が選択できるほどの言語材料を持っていなければ選択すらできないというならば,なぜ中学校教科書では学年があがるにつれてコミュニケーション活動そもののの割合すら減っていってしまうのか(先述の研究の結果明らかになったこと)。学年があがるにつれて選択できる材料は増えていくはずなのだから,学年があがるにつれて選択の機会を増やしていくべきなのではないのか。高校に行ったらその機会ももっともっと増えていくはずなのではないのか。実際に行われている指導はそのようになっているだろうか。そう考えると,選ぶほどの材料がないから,というのは批判の理由にならない。教えないとできないと勝手に思っているから批判するのであって,さらにその「できる」も「(正確に文法的な誤りを犯すことなくかつ流暢に)できる」ことを意味しているからこそ選択させる前に教えたがるのだろう。
繰り返しになるが,先に教えることそれ自体が選択する機会を奪う可能性をはらんでいる。特に(学校的な意味で)真面目な学習者ほど,教わったことを使うことが求められていると思ってしまいがちな気もするからである(ただの推測)。
何が言いたいのかよくわからなくなってしまったが,とにかく,英語の授業の中で,「どうやって言うか」という言語形式を「選ぶ」機会がどれだけあるか,ちょっと振り返ってみませんかね?ということ。実はこの記事は約2週間前に書いていたものなのだが,ここ最近anfieldroad先生(もしかして徳島以来お会いしてないかも…)がブログ記事で書いていらっしゃる「お皿」と「お肉」の喩えともリンクするところがあるように思う。anf先生は,「何を言うか」はとりあえず与えてしまってもいいから,「どうやって言うか」にあたる「お皿」選びをできるようにさせたいというお話。タスクはこの辺は結構融通がきいて,シンプルな情報交換タスク(e.g., 間違い探し)なら伝えるべき情報はそこにあるという状態だが,意思決定タスク(e.g., 無人島タスク)になれば,まず「無人島に何を持っていくか」を考える必要があるし,「なぜそれを持っていくのか」を考える必要も出てくる。さらにはタスク中にはグループのメンバーの話を聞き,「どうやって説得して自分の意見を主張するか」も考える必要がある。事前のプランニングタイムを与えるにせよ,お皿に盛り付ける料理とそれを盛るお皿(もしかしたらお椀や丼ぶりかもしれないが)を両方考える必要が出てくるというわけだ。
冒頭で紹介した本はもっともっと教育の根本的な問題についての話であり,「選ぶ力」というものが意味するところももっと幅も広いし奥も深い。しかしながら,英語の授業に限定して考えた場合,「適切に」「正確に」言語を使用するために何かを選ぶ作業は結局著者の批判するテストの答えを覚えることに等しいのではないかと思う。そうではなくて,伝えようとすることを伝えるために何かを選ぼうとし,そこで,迷い,悩む,という経験自体は,著者のいう「選ぶ力」に通じるものがあると私は思っている。
なにをゆう たむらゆう
おしまい。

蒸し鶏と白菜の和え物

卵焼き(青のり入り)

カジキマグロステーキの野菜あんかけ

厚揚げと玉ねぎの煮物

麻婆豆腐。かなりイマイチだった。

バンバンジー

小松菜のオイマヨ炒め
ちょっとわけあって,欠損値の処理について勉強するソルジャー業務機会がありました。そこで,多重代入法(MI: Multiple Imputation)という方法をRで実行する方法を少しかじったのでメモ代わりに残しておきます。
ちなみに,欠損値の分析をどうするかという話は全部すっ飛ばしますのでそのあたりは下記リンクなどをご参照ください。
多重代入法に関してはこのあたりの資料をどうぞ。
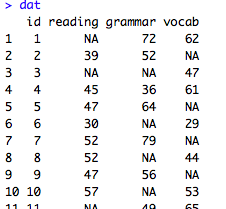
#まずはデータセットの下準備。こんな仮想データだとします。
#id =参与者ID, reading = 読解テストの得点,grammar = 文法テストの得点,vocab = 語彙テストの得点
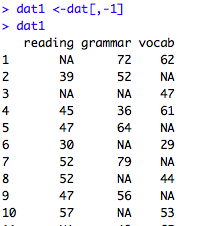
#id列はいらないのでid列を抜いたデータセットを作る
dat1 <-dat[,-1]
#欠損を可視化するにはVIMというパッケージが便利
install.packages(“VIM”)
library(VIM)
#欠損情報を入手
m <-aggr(dat1)
#うまくいくとこんな感じで欠損情報を可視化してくれます
左側が欠損の割合で,右側が欠損のパターン。赤い所が欠損です。
#数値で確認する場合はmの中身を見る
#Multiple Imputation by a bootstrappted EM algorithm (Amelia Package)
#パッケージのインストール
install.packages(“Amelia”)
library(Amelia)
#amelia()関数をまずは使います
#引数は以下のとおり
#x = data.frame
#m = 何個のデータセットを作るかの指定
#dat1.outという変数に,多重代入した結果を入れます
dat1.out <-amelia(x = dat1,m = 5)
#中身はsummaryで確認します
summary(dat1.out)

#補完データの分散共分散行列をみる
dat1.out$covMatrices

#補完データを書き出し
#separate =Fと指定すると,データが1つのファイルに書きだされます
#separate = Tにすると,データセット1つにつき1ファイルで書きだされます
#dat1.ameria.csv, dat1.ameria1.csv, … dat1.ameria5.csvみたいな感じで番号をつけてくれます
#orig.data=Tで,オリジナルのデータを出力する際に含めるかどうかの指定ができます
write.amelia(obj = dat1.out,“dat1.amechan”,separate=T,orig.data = F)
#AmeliaView()を使うと,GUIで操作できます(重いです)
AmeliaView()
#多重代入した結果得られた補完データをまとめる作業をします
#例として重回帰分析をやってみます
#独立変数 = grammar, vocab
#従属変数 = reading
m =5
b.out <-NULL
se.out <-NULL
for(i in 1:m){
ols.out <-lm(reading ~ grammar+vocab,data=dat1.out$imputations[[i]])
b.out <-rbind(b.out, ols.out$coef)
se.out <-rbind(se.out, coef(summary(ols.out))[,2])
}
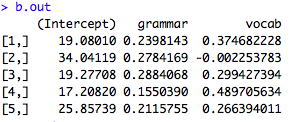
#b.outにはbetaが5つ入っています
b.out
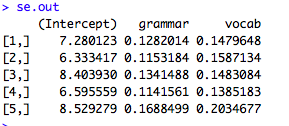
#se.outには標準誤差(SE)が入っています
se.out
#mi.meld()で,5つのbetaとSEをまとめます
combined.results<-mi.meld(q = b.out, se = se.out)
combined.results
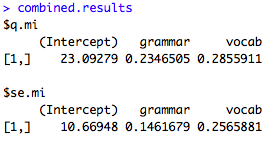
SEがちょっと広めですかね
というわけで,まとめる段階が手動で関数書いていますが,それ以外は割りと簡単にできます。ファイルの書き出しなんかもできますし。
補足
miceパッケージを使うともっと簡単に多重代入->分析->統合ができるようです。
install.packages(“mice”)
library(mice)
imp_data<-mice(dat1,m = 5)
fit <-with(imp_data,lm(reading ~ grammar + vocab))
summary(pool(fit))

まぁまぁ結果は近い?
なんかmiceパッケージの方が使い勝手が良さそうですね(アレレ
ちょっとまた時間があったらもう少し勉強してみたいと思います。
今日はこのへんで。
なにをゆう たむらゆう
おしまい。