
はじめに
いままであまり深く考えたことなかったんですけど,多肢選択式のテストを作るとき,正答をどれに指定するかって規則性がないように,同じものが連続にならないように,とかを「なんとなく」,「雰囲気で」やってきたところがあります。それを,ちゃんとランダムにできないかな,というお話。
R編
なにはともあれ,Rを使います。エクセルでもできるのにRです。Rなら一瞬です。
sample関数とLETTERS関数の組み合わせ
要するに,例えば4択問題であればABCDの4つの中からランダムに1つ選ぶのを問題数分だけ繰り返すってことになりますよね。それを表現してあげれば良いだけです。めっちゃ簡単。
例として,ABCDの4択問題を20問作ることにしましょう。
sample関数を使います。sample関数は次のような引数を取ります。
sample (x, size, replace = FALSE, prob = NULL)- x: もとデータのベクトル(今回はこれをABCDにしたい)
- size: サンプリング回数(20問なのでここに20をいれる)
- replace: 繰り返しありかどうか(デフォルトだとFALSEで同じものが繰り返し出てこないようになってますが,今回はむしろ繰り返し出てきてOKなのでTRUEにしないとだめ)
- prob: サンプリングの重み付け確率(どれが何%の割合でてくるようにするか決められます。後述します)
さて,次に問題になるのは,ABCDをベクトルにすることですね。もちろん,
> d <- c("A", "B", "C", "D")で簡単にできます。よって,
> d <- c("A", "B", "C", "D")
> sample (d, 20, replace = TRUE)これでOKです。ただ,ほんのちょっとだけ便利なやり方は,LETTERSを使うことです。Rはデフォルトで,LETTERSの中に,A~Zまでのアルファベットが入っています(小文字のa~zはlettersです。
> LETTERS
[1] "A" "B" "C" "D" "E" "F" "G" "H" "I" "J" "K" "L" "M" "N" "O" "P" "Q" "R" "S" "T" "U" "V" "W" "X" "Y" "Z"
今回は,A~Dの4つだけでいいので,1番目から4番目までをつかいます。sample関数と組み合わせて…
> sample(LETTERS[1:4],20,replace = TRUE)
[1] "B" "D" "C" "A" "D" "D" "C" "A" "A" "C" "B" "A" "D" "A" "B" "C" "C" "C" "A" "C"これでばっちりですね。もしも,「えーなんかこれC多くない?」みたいなことが気になる方はこのコード何回か走らせていい感じの組み合わせが出たらそれを使えばいいんじゃないかと思いますが,probでABCDがでる確率の重み付けをつけてあげることもできます。
> sample(LETTERS[1:4],20,replace = TRUE, prob=c(0.25,0.25,0.25,0.25))
[1] "D" "B" "A" "C" "C" "A" "C" "D" "C" "A" "A" "C" "B" "B" "B" "D" "B" "D" "B" "D"絶対にいつでも等確率で現れるわけではないみたいで,4つだったり6つだったりするものもありますが,完全なランダムよりは出現確率が揃ってるんじゃないかなと。もしもこれをエクセルにはりつけたければ,出力されたものをそのままコピペして,Text Import Wizardでスペース区切りにしてあげればOKです。縦にしたい場合は転置してください。

Excel編
Excelでもそこまで難しくないです。INDEX関数とRANDBETWEEN関数を組み合わせます。下の画像のようにすればOKです。
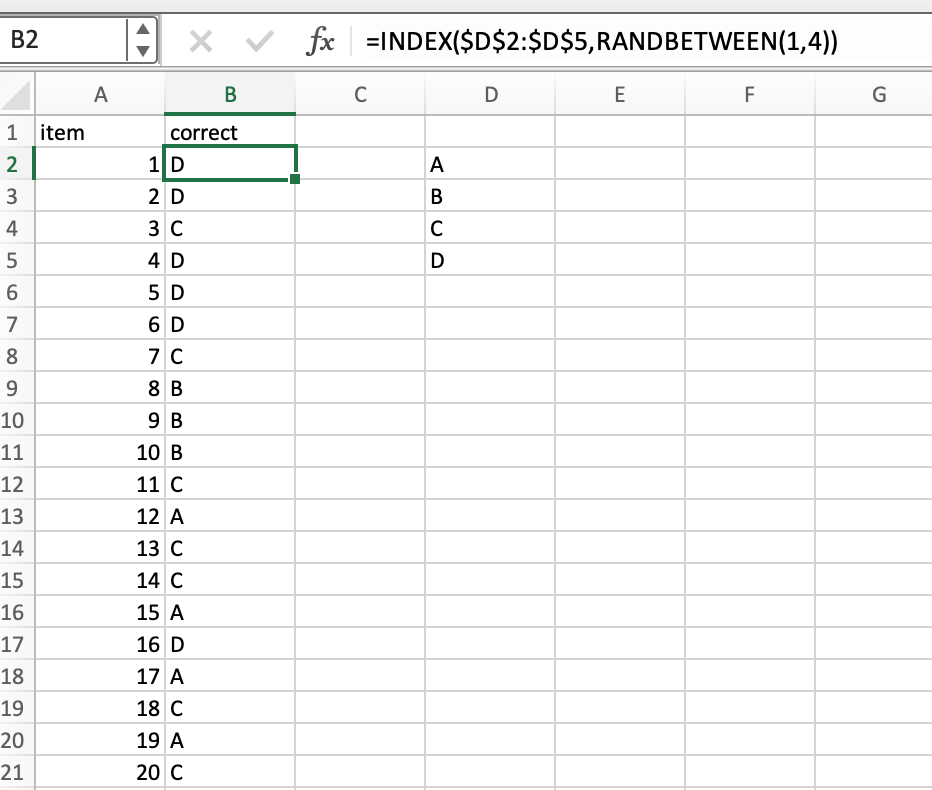
B3からB21までは,B2を下にコピーしたものが入ってます。INDEX関数の第一引数で参照元の範囲をしています。これがつまりABCDってことですね。そして,次の引数が縦位置の指定です。本当はこの後ろの第三引数で横位置指定もできますが,今回は1列だけなのでこれでOKです。この位置指定が1のときはA,2のときはB,3のときはC,4のときはDってな感じになるというわけです。そして,RANDBETWEEN関数をここに使うことで,1から4がランダムに出てくれる=ABCDがランダムに出てくれる,ということになります。ちなみに,RANDBETEEN関数は,始点と終点の数値を入れればその間の整数をランダムに返す関数です。
ちなみに,横位置指定を使おうと思えば,ABCDを1列ではなく2列に分割することになります。こちらのほうが数式が長くなるのでおすすめしないですが,INDEX関数の挙動のイメージを理解するために見てみます。

こっちだと範囲が2*2のマトリックスになるわけですね。そして,第二引数(縦位置指定)で1か2のどちらかの数字,第三引数(横位置指定)で1か2のどちらかの数字をランダムに返すようになっています。つまり,(1, 1), (1, 2), (2, 1), (2, 2)の4つのパターンがランダムにできて,それに対応するABCDが返ってきます。(1, 1)ならAというような感じ。もっと大きなデータを扱う場合には縦横指定が必要になるでしょうが,今回の用途には不要なので,ABCDを一列にするほうがいいと思います。
おわりに
別に適当に正答指定して何も悪いことはないのですが,ランダムにするのってできるかな?という頭の体操でした。
なにをゆう たむらゆう。
おしまい。

