ポークソテートマトソース

ポークソテートマトソース
「なぜ学校へ行くのか」という本を読んだ。途中までずっと積読状態になっていたのだけれど,ふと最近また本を読んでないなと思って再開した。第3章あたりから,人間の本質的な能力であり,人間らしさの根源である選択能力,選ぶ力,という話が出てくる。人間は生まれてからずっと様々な選択を繰り返していく生き物であり,選択することができるというのが人間であることであるというような事が述べられている。しかしながら,学校ではこの選ぶ力を育てることができていないのが現状ではないかというのが著者の主張である。
この主張を自分の興味関心や研究に引きつけて考えたときに,タスクのことが思い浮かんだ。別にタスクである必要はないのだけれど,新しい言語項目を教える->練習する->使う,というような手順の指導のことを考えたのだ。いわゆるPPP(Presentation-Pracice-Production)というやつ。そう,この指導過程の中には,学習者が何かを「選ぶ」という過程が全く無いではないかと考えたのだ。いや,まったくないとも言い切れないかもしれない。例えば,いわゆるfill-in-the-blank exerciseのような課題を練習セクションで行ったとすると,そのカッコに何が入るのかを「選ぶ」という作業は確かに発生するからだ。ただし,実際に言語を使う際に,あるカッコに何が入るかを「選ぶ」という作業の必要性が発生する場面があるだろうか。昨年中部地区英語教育学会にて発表した中学校教科書分のタスク性分析研究(たぶんそろそろ投稿する)のときにも散々主張したことであるのだが,「何を言うのか」を考えて,それを「どのような言語形式で表現するのか」という過程を体験することは,中学校教科書に掲載されているコミュニケーション活動を行っただけではほとんどできないと言っていい。
しかしながら,この過程を体験する事こそがまさに「選ぶ力」につながるのではないだろうか。「どのような言語形式で表現するのか」を「選ぶ」というのが,産出の際には非常に重要になってくる。そこを考える,何を選択すべきなのかに思いを巡らせることがほとんどないということの背景には様々なものがあろうだろう。著者は,テストの点数で能力を測定しそれによって序列化することを問題点として挙げ,その影響で,とにかく問題の答えを知りたがる子どもができあがっている,問題から答えに至るまでの過程をすっ飛ばして答えを暗記することを暗に助長してしまっていると述べている。
英語の授業(テスト)を考えみると,正確さの重視というものが,問題の答えだけを知りたがるという状況を作り出してしまっているのかもしれない。とにかく誤りがあれば減点されるわけなので,誤りのない表現が欲しい。なので,「なぜその言語形式なのか」はすっ飛ばしても,この表現なら間違いがないというものを持っていれば安全なのだ。
タスクを遂行することを考えてみる。タスクは文法的な正確さで評価をされず,タスクが達成されたかどうかが評価の基準となる。「正しい」か否かで評価されることがなければ,とにかく自分の伝えようとしていることが相手に伝わるかどうかという点だけに学習者は集中する事ができる。そういう状況では,自分が伝えようとしていることをどのような言語形式で表現したらいいのかを考えて選択し,まず頭に思い浮かんだ表現で伝えてみるだろう。もしその表現で伝わらなかったという場合には,ではどのような別の表現を使えば相手に伝わるのだろうかとさらに考えて選択を行う必要が生じるはずだ。
いくら練習に練習を重ねても,「何を言うべきか」と「どう伝えるべきか」という2つの選択をする機会が保障されなければ,その日に習った表現をその日に使うことはもしかするとできるようになるかもしれないが,どのような表現を使うべきかの選択が迫られるコミュニケーション(実際に起こるコミュニケーションではこれが当たり前のはず)場面では何も言えずに終わってしまうだろう。
タスクの話をすると教えることを軽視しているというような批判をよく受けるが,教えるなとは言っていない。教えてもいいから,教えたことを使うということに終始せずに,とにかく「選択する力」を養うことができる機会をもっともっと増やしませんかと言っているだけなのである。学習者が選択できるほどの言語材料を持っていなければ選択すらできないというならば,なぜ中学校教科書では学年があがるにつれてコミュニケーション活動そもののの割合すら減っていってしまうのか(先述の研究の結果明らかになったこと)。学年があがるにつれて選択できる材料は増えていくはずなのだから,学年があがるにつれて選択の機会を増やしていくべきなのではないのか。高校に行ったらその機会ももっともっと増えていくはずなのではないのか。実際に行われている指導はそのようになっているだろうか。そう考えると,選ぶほどの材料がないから,というのは批判の理由にならない。教えないとできないと勝手に思っているから批判するのであって,さらにその「できる」も「(正確に文法的な誤りを犯すことなくかつ流暢に)できる」ことを意味しているからこそ選択させる前に教えたがるのだろう。
繰り返しになるが,先に教えることそれ自体が選択する機会を奪う可能性をはらんでいる。特に(学校的な意味で)真面目な学習者ほど,教わったことを使うことが求められていると思ってしまいがちな気もするからである(ただの推測)。
何が言いたいのかよくわからなくなってしまったが,とにかく,英語の授業の中で,「どうやって言うか」という言語形式を「選ぶ」機会がどれだけあるか,ちょっと振り返ってみませんかね?ということ。実はこの記事は約2週間前に書いていたものなのだが,ここ最近anfieldroad先生(もしかして徳島以来お会いしてないかも…)がブログ記事で書いていらっしゃる「お皿」と「お肉」の喩えともリンクするところがあるように思う。anf先生は,「何を言うか」はとりあえず与えてしまってもいいから,「どうやって言うか」にあたる「お皿」選びをできるようにさせたいというお話。タスクはこの辺は結構融通がきいて,シンプルな情報交換タスク(e.g., 間違い探し)なら伝えるべき情報はそこにあるという状態だが,意思決定タスク(e.g., 無人島タスク)になれば,まず「無人島に何を持っていくか」を考える必要があるし,「なぜそれを持っていくのか」を考える必要も出てくる。さらにはタスク中にはグループのメンバーの話を聞き,「どうやって説得して自分の意見を主張するか」も考える必要がある。事前のプランニングタイムを与えるにせよ,お皿に盛り付ける料理とそれを盛るお皿(もしかしたらお椀や丼ぶりかもしれないが)を両方考える必要が出てくるというわけだ。
冒頭で紹介した本はもっともっと教育の根本的な問題についての話であり,「選ぶ力」というものが意味するところももっと幅も広いし奥も深い。しかしながら,英語の授業に限定して考えた場合,「適切に」「正確に」言語を使用するために何かを選ぶ作業は結局著者の批判するテストの答えを覚えることに等しいのではないかと思う。そうではなくて,伝えようとすることを伝えるために何かを選ぼうとし,そこで,迷い,悩む,という経験自体は,著者のいう「選ぶ力」に通じるものがあると私は思っている。
なにをゆう たむらゆう
おしまい。

蒸し鶏と白菜の和え物

卵焼き(青のり入り)

カジキマグロステーキの野菜あんかけ

厚揚げと玉ねぎの煮物

麻婆豆腐。かなりイマイチだった。

バンバンジー

小松菜のオイマヨ炒め
ちょっとわけあって,欠損値の処理について勉強するソルジャー業務機会がありました。そこで,多重代入法(MI: Multiple Imputation)という方法をRで実行する方法を少しかじったのでメモ代わりに残しておきます。
ちなみに,欠損値の分析をどうするかという話は全部すっ飛ばしますのでそのあたりは下記リンクなどをご参照ください。
多重代入法に関してはこのあたりの資料をどうぞ。
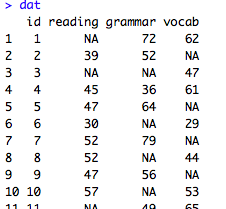
#まずはデータセットの下準備。こんな仮想データだとします。
#id =参与者ID, reading = 読解テストの得点,grammar = 文法テストの得点,vocab = 語彙テストの得点
#id列はいらないのでid列を抜いたデータセットを作る
dat1 <-dat[,-1]
#欠損を可視化するにはVIMというパッケージが便利
install.packages(“VIM”)
library(VIM)
#欠損情報を入手
m <-aggr(dat1)
#うまくいくとこんな感じで欠損情報を可視化してくれます
左側が欠損の割合で,右側が欠損のパターン。赤い所が欠損です。
#数値で確認する場合はmの中身を見る
#Multiple Imputation by a bootstrappted EM algorithm (Amelia Package)
#パッケージのインストール
install.packages(“Amelia”)
library(Amelia)
#amelia()関数をまずは使います
#引数は以下のとおり
#x = data.frame
#m = 何個のデータセットを作るかの指定
#dat1.outという変数に,多重代入した結果を入れます
dat1.out <-amelia(x = dat1,m = 5)
#中身はsummaryで確認します
summary(dat1.out)

#補完データの分散共分散行列をみる
dat1.out$covMatrices

#補完データを書き出し
#separate =Fと指定すると,データが1つのファイルに書きだされます
#separate = Tにすると,データセット1つにつき1ファイルで書きだされます
#dat1.ameria.csv, dat1.ameria1.csv, … dat1.ameria5.csvみたいな感じで番号をつけてくれます
#orig.data=Tで,オリジナルのデータを出力する際に含めるかどうかの指定ができます
write.amelia(obj = dat1.out,“dat1.amechan”,separate=T,orig.data = F)
#AmeliaView()を使うと,GUIで操作できます(重いです)
AmeliaView()
#多重代入した結果得られた補完データをまとめる作業をします
#例として重回帰分析をやってみます
#独立変数 = grammar, vocab
#従属変数 = reading
m =5
b.out <-NULL
se.out <-NULL
for(i in 1:m){
ols.out <-lm(reading ~ grammar+vocab,data=dat1.out$imputations[[i]])
b.out <-rbind(b.out, ols.out$coef)
se.out <-rbind(se.out, coef(summary(ols.out))[,2])
}
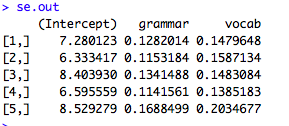
#b.outにはbetaが5つ入っています
b.out
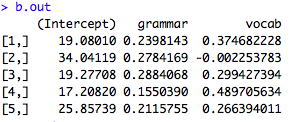
#se.outには標準誤差(SE)が入っています
se.out
#mi.meld()で,5つのbetaとSEをまとめます
combined.results<-mi.meld(q = b.out, se = se.out)
combined.results
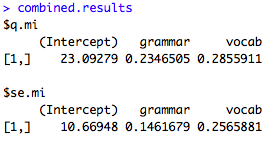
SEがちょっと広めですかね
というわけで,まとめる段階が手動で関数書いていますが,それ以外は割りと簡単にできます。ファイルの書き出しなんかもできますし。
補足
miceパッケージを使うともっと簡単に多重代入->分析->統合ができるようです。
install.packages(“mice”)
library(mice)
imp_data<-mice(dat1,m = 5)
fit <-with(imp_data,lm(reading ~ grammar + vocab))
summary(pool(fit))

まぁまぁ結果は近い?
なんかmiceパッケージの方が使い勝手が良さそうですね(アレレ
ちょっとまた時間があったらもう少し勉強してみたいと思います。
今日はこのへんで。
なにをゆう たむらゆう
おしまい。
気づいたらクリスマスも終わってどうやら2015年も残すところあと数日で終わってしまうようですね。ということで,今年も1年を振り返ってみたいと思います(2014年の振り返りはこちら)。
2015年は,自分の書いた論文が初めて出版された年でした。投稿したのは2014年中だったものが多いですが,出版されたのは2015年なので,私の研究者人生も2015年からスタートしたようなものです。
1月はD1報告の準備を泣きそうになりながらやっていました。博士後期課程に入学したときとは全く違うテーマに変えたので,論文を何十本も読みながら計画を練り直したのを覚えています。そのテーマで博士論文を書くことに決めたので,そういう意味でも2015年はターニングポイントだなと思っています。2月には基礎研の年次例会があったり,3月はあっという間にすぎていきました(たぶん)。
今年度はD2になり,先輩におんぶにだっこだった昨年度よりも自分で研究をガンガン進めていく立場にならないといけないと思い,後輩と一緒に研究プロジェクトをいくつかやりました。それらを中部地区英語教育学会(和歌山),言語科学会(大分),全国英語教育学会(熊本)で発表しました。今年は色々なところに出向いて学会発表をし,美味しいものをたくさん食べられたのもいい思い出です。来年は東京の学会が多いのが少し残念ではありますが…(実家に滞在すればよいので滞在費とか削減できるのは良いですけど)。
夏がすぎると論文執筆の時期…のはずだったのですが,全然筆が進まず,スケジュール管理と目標設定を意識的にやりながらなんとか論文を進めていたのが9-11月あたりでしょうか。
7月には母方の祖父が亡くなりました。祖父は長野県で教員をやっていたので,僕が教師を目指していたことをとても喜んでいました。教員をやっている姿を見せられなかったことが今でも残念ですが,僕は僕なりに一生懸命頑張って,この道で生きていこうと思います。
そういえば,基礎研の部会長にもなりました。会の運営は色々大変なこともありますが,川口くんと協力しながらなんとかやっています。彼は本当に優秀で,一緒に仕事するのがとても楽ですね。僕がわりと好き勝手にやれているのも,彼がいるからだと思います。感謝しています。今後も会が続いていくように,色々考えて動いていきたいと思います。
昨年の今ごろも博論やりたくないとうだうだ言っていましたが,今年も同じで1月のゼミ発表と2月のD2報告が今は嫌で嫌で仕方ありません…(準備は全然進んでいませんヒィィ
そういえばツイッターも事実上やめました。アカウントは消してませんが(理由はこちら)。今はFacebookはたまに覗いていますけどね。自分のことをウェブ上に発信するのはブログでやっていこうと思います。色々ありましたが,私は元気にやっています。
というわけで,2015年も健康上特に大きな問題もなく過ごすことができました(初めて虫歯の治療したというのはありましたが)。2016年も,健康に過ごせるよう,たまには息抜きをして,自分のできる範囲で自分のできることをコツコツやっていこうと思います。
それではみなさま,良いお年を。
なにをゆう たむらゆう
おしまい。

特急しなの

部屋からの夜景

貸し切りのお風呂

前菜。奥から時計回りで手長海老と桜海老真薯,百合大根干し柿巻,鰊青唐醤油漬け,白子豆腐,紫芋チーズ

目鯛,マグロ,大岩魚のお造り

投汁蕎麦

茶碗蒸し

釜飯

玄米饅頭

林檎グラタン

地ビール

ワイン豚のワインしゃぷしゃぷ

東寺揚げ,養老揚げ,獅子唐

松本城

別アングルからの松本城

時計博物館

ローリング・ボール・クロック。球がジグザクに左右に動きながら時を刻むという。この技術にはびっくり。
先日ついにtidyrパッケージで縦横変換をやってみた。今までずっと覚えなきゃなと思ってて結局億劫でやってなかったんだけれど手伝いで仕方なく。
データハンドリングで,横に広がる(列数の多い)wide-formatのdataを分析に便利なlong-formatに変換するというのは,分析をやるまえのデータ整形の過程で必ず通らなければならない道。Excel上で地道にやるのもあるにはあるだろうけど,Rのtidyrを使えばすぐできるというお話。これ系の話はググればネット上にゴロゴロ記事が転がっている。なので,今回は具体的に外国語教育研究系のデータ分析ではどんなときに役に立つかなーという話です。特に無駄に変数が多い時なんかは結構役に立つと思います。

sample data
適当にこんな感じでデータが入っているとします(数値は乱数)。事前・事後・遅延事後のテストがあって,それぞれで流暢さ(fluency),正確さ(accuracy),複雑さ(complexity)の指標があるみたいな。1列目には被験者番号があって,それぞれの列名は”test.measure”という感じでドット区切りにしてあります。で,これを,「事前・事後・遅延事後」の3つのカテゴリカル変数からなる”test”列と,3つの指標(CAF)の”measure”列の2列に分解しましょうという話し。
R上に上のようなデータを読み込みます。

read.table関数で読み込んだ場合(※MacなのでちょっとWindowsと違います)
まずはパッケージの準備
install.packages(“tidyr”) #パッケージのインストール
library(tidyr) #tidyrパッケージの呼び出し
datに入っているデータフレームをまずは,変数名の列(variable)とその値(value)の列に集約します。key=変数名の列,value=値の列という引数指定です。
#%>%はパイプ演算子。以下の関数で扱うデータフレームを指定するということです
dat %>%
#-subjectでsubjectの列を除外。変換したdataをdat2に入れる
gather(key = variable,value = value,-subject) -> dat2
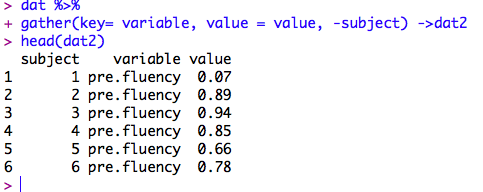
long formatのデータに変換されました
これで変数名を1列に集約できました。ただし,この列にはpre, post, delayedというテスト実施時期の情報と,fluency, accuracy, complexityという指標の情報が混ざってしまっています。これを,2列に分けます。
dat2 %>%
#colで分けたい列名,intoで分けた後の列名を指定。sepでセパレータを指定しますが,デフォルトはあらゆる非アルファベットになっているので,ドットなら指定しなくても大丈夫
separate(col = variable, into = c(‘test’, ‘measure’)) -> dat 3
さて,dat3の中身を確認してみると…

long formatのデータに変換されました
おおおおー!!!!!
というわけで,横に変数がたくさんある場合もこのtidyrのgatherとseparateを使えば簡単にlong型に変換できそうです。
参考サイト:http://meme.biology.tohoku.ac.jp/students/iwasaki/rstats/tidyr.html
なにをゆう たむらゆう
おしまい。
ストレスが溜まっているのかなんなのか帰り道にセブン-イレブンでチーズとワインを買って飲むとかいう珍しいことをしているという言い訳を最初に書いておこうと思います。それから,自戒もたっぷり込めていることも申し添えておきたいと思います。
データ分析の方法の相談についてです。色んな所で起こっていることだと思うし色んな人がきっと同じようなことを考えているだろうと思います。一言でいうと,データを取る前に相談してみましょうということです。データを取ったあとに,「このデータってどうやって分析すればいいですか?」っていう質問は結構つらいところがあったりします(恐れ多くもなぜだかこういう質問をされる立場に私もなってしまいました)。なぜなら,本当にその質問者の方が調べたいこと,明らかにしたいことが,そのデータ収集方法で明らかにすることができるのかちょっと怪しかったりすることがあるからです。
そういう状況にならないために重要なことは,研究課題を見つけて,それを具体的な実験計画なりに落としこむ際に,その先のことまでちょっと考えてからデータ収集をしてみることだと思います。つまり,
こういう方法を使うと,こういうデータを収集することができる。それをこういう分析にかければ,こういう結果が得られるはず。もしこういう結果が得られた場合,それはこういうことを意味していると解釈できるだろう。
みたいなことを考えてから実験を組んで,データを取っていただきたいなということです。そうすれば,データを取ってからどうしたらいいかという質問が来ることはなくなるからです。上述の事でイマイチ自分がうまく説明できないとなったら,その時点で相談をすればよいと思います。そうすれば,実はその方法で得られたデータで,質問者の方の主張をするのはちょっと違うので,こういうデータ収集をしないといけませんよ,なんてアドバイスができたりするかもしれないからです。これって仮説検証型の研究でも探索的な研究でも同じだと思います。たとえ探索的な研究だったとしても,得られた結果に対してなんらかの解釈を加える必要はあるはずですから。研究課題がwh疑問文で始まる形であったとしても,結果に対しては,きっとこういう理由でこうだったのだろうということを言えなければいけないわけですし。
データをとって,分析をしてみて,これであってるのか不安だから相談してみようということもあるのかもしれませんが,それって別にデータ取る前にもできることなんですよね。
こういう研究課題をもっていて,これを明らかにするためにこういう分析をしてこういう結果が得られたらこういう解釈ができると思うのですが,これで合ってますか?
ってデータ取る前に相談すればすむと思うのです。なのにどうして,「データを取ったあとにこれってどうやって分析すればいいんですか?」ってなってしまうのでしょう。
これはあくまで持論なのですが,研究って,研究のデザインとか実験計画ですべて決まると私は思っています。面白いなと思う研究はやっぱりデザインがしっかりしていて,分析の結果から得られたことの解釈がとってもシンプル(注1)なんです(そういう研究が良い研究だと思う私からすると,discussionを長々と書いている論文やそれが良しとされる風潮,また「discussionが短い」みたいなコメントってなんだかなと思ったりします)。それって,デザインを練る段階で色んなことを考えているからなんですよね。研究の計画を立てる段階で,データの分析方法まで明確にイメージできない場合は,データ収集に入るべきではないと私は考えています。私の場合は基本的に,ある研究で行われることを考えることは,R上で分析を行う際のデータセットの形をイメージすることとほぼ同義です。変数のデータフレームがイメージできていて,それをどうやって分析すれば何をどうしていることになるのか,こういう結果になったらそれはどう解釈するのか,また別の結果がでたらそれをどう解釈するのかまで考えられて初めて研究のデータ収集ができるのではないでしょうか。
こういった考えが当たり前になれば「統計屋さん」(私は違いますけど)とか言われる人たちもずいぶん楽になるのではないかなと思っています。
なにをゆう たむらゆう
おしまい。
*注1: だからといって,t検定一発で明らかになることってそんなにはないとは思います。少なくとも今なら昔はt検定一発だったこともGLMMするでしょう。例えば正答率の平均値をt検定というのはもはや時代遅れになりつつあるわけですし。
明日8日(日)の夜に名古屋に戻ることになりました。