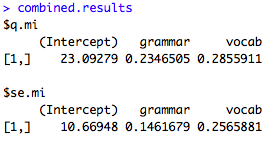
RでGLMMするときに使うglmer関数。要因の水準が3以上になると,どうしても多重比較したくなっちゃいますよね。けれど,デフォルトでは全水準の総当り比較はできない。そんなときにはlsmeans関数が便利です。ところが,glmer関数の出力結果をいれた変数を使ってlsmeans関数に渡してもなんかエラーメッセージが出てしまいました。
Error in format.default(nm[j], width = nchar(m[1, j]), just = "left") : 4 arguments passed to .Internal(nchar) which requires 3
こういうやつ。Rでエラーメッセージが出て,その原因がよくわかんなかったらもうそのエラーメッセージをそのままコピペしてググってしまうと。そうするとたいてい同じ悩みで困っている人の書き込みとかがヒットすることがしばしばあります。
するとこのサイトがヒット。
Error in R lsmeans() function: Error in format.default(nm[j], width = nchar(m[1, j]), just = “left”)
この掲示板の書き込みを見てみると,どうやらRのバージョンが古い(R3.2.0以前)とこのエラーメッセージが表示されるらしいです。なんか根本的な解決にはなってないような気もしますが…
とはいえ私もR3.2.0ユーザーだったので,これを気に新しいRをインストールすることに。R.3.3.0が最新らしいです。最新のに変えると今まで使ってたパッケージに不具合が出たりすることがあって不安でしたが,実際にRのバージョンを新しくすればglmerのあとに多重比較ができました。
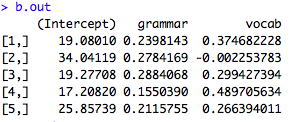
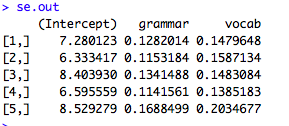
fit1<-glmer(RT ~presentation*condition+ (1|subject) + (1|item), family = Gamma (link= “identity”), data=dat,glmerControl (optimizer=”bobyqa”)
lsmeans(fit1, pairwise~condition|presentation)
こんな感じ。
要因の順番は,多重比較したい要因が先にきます。つまり,上の例だと,condition条件の多重比較をpresentation条件ごとにやるという感じです。逆にすれば,presentation条件の多重比較をcondition条件ごとにやることになります。
もちろんコーディングを変えて全条件の組み合わせをつくればlsmeansとかしなくてもglmerだけで大丈夫ですし,例えば1, 2, 3と水準があったときに,1と2,3をまとめた水準を比較して違うか調べたいときとか(例えば英語母語話者が1で日本語母語話者が2, 韓国語母語話者が3で,母語話者群と学習者群が異なるか調べたいとか)には,やはり自分でコーディングを変えないといけません。カテゴリカル変数のコーディングの違いについてはこのサイトがわかりやすいです。
R Library: Contrast Coding Systems for categorical variables
しかしもはやこれでANOVAする必要が本当にないのではないかと…
そういえば,ついにdplyrの基礎がわかってなにこれめちゃ便利って感動したのでそのこともまた書きます。
なにをゆう たむらゆう。
おしまい。