Tamura, Y. (2026). Singular–plural asymmetry in L2 English number processing: A sentence-picture matching study of Japanese learners of English. International Journal of Bilingualism. https://doi.org/10.1177/13670069261422017
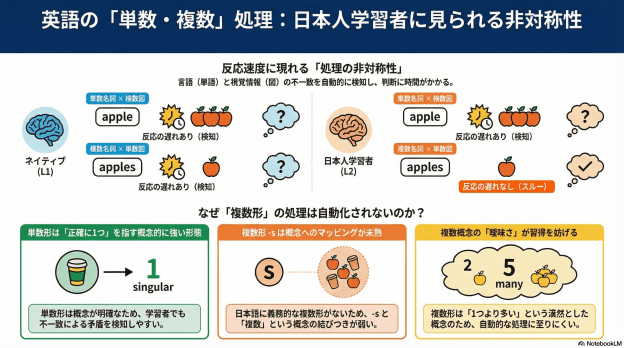
先行研究(Jiang et al., 2017)では,文中に単数形名詞が出てきたとき,それが複数の物が写っている写真とペアになると,母語話者の反応時間が遅くなることが示されていました。これは,文処理中に単数形の意味(=1つ)が自動的に活性化され,写真の内容との概念的な不一致が干渉を生んでいることを意味します。ただし,Jiang et al. の研究では「単数名詞×複数の写真」という一方向のミスマッチしか検討されていませんでした。では逆方向,つまり「複数形名詞×1つの物の写真」ではどうなのか,については誰も調べていなかったのです。
この非対称性の説明として,本研究では意味的有標性(semantic markedness)の概念を援用しています。単数形の意味(=正確に1つ)は精確で特定性が高いのに対し,複数形の意味(=1より多い)は本来ぼんやりしていて,特定の数を指すわけではありません(Sauerland et al., 2005; Patson et al., 2014)。学習者にとっては,この「単数のクリアさ」があるからこそ自動的な概念マッピングが成立するが,「複数の意味のぼんやりさ」に加えて,日本語には義務的な複数形形態素が存在しないという母語の影響(Morphological Congruency Hypothesis; Jiang et al., 2011)も重なり,複数形と複数概念のリンクが自動化されるに至っていない,という解釈です。
最初は,元の研究になっているJiang et al. (2017)の追試研究として書きました。もともと博論を構成する研究のうちの一つだったのですが,そのときは実験2つを組み合わせた解釈をしてたから割といけたんですが,この実験だけ取り出して新規性とか議論を膨らませるのが結構難しくて,全然書き進められていなかったのが原因でした(5000語くらいでずっと塩漬けになっていました)。
英語には,名詞の単数・複数を形で区別する仕組みがあります。この複数形形態素の習得というのは,簡単そうに見えて実は数の一致の誤りにはなかなか気づけないこともあるなど,第二言語習得研究の関心事でした。私の博士論文は,「数の一致」の誤りに気づけるかどうか,という,いわゆる誤文反応検知(anomaly detection) 先行研究(Jiang et al., 2017)では,「単数形の名詞と複数の絵を見せると,母語話者は処理が遅くなる」という結果が示されていました。つまり,頭の中で「あれ,合ってないぞ」という衝突が起きるわけです。
ところが,Jiang et al. (2017)では,「単数形名詞 vs. 複数の絵」という実験はありましたが,「複数形名詞 vs 1つの絵」(実験3)では常にseveralやtwo,manyのような語彙的な複数を表すマーカーが含まれていて,これがあると不一致条件で遅れが出る(例:several paper bagsと読んでbagが一つだけなら遅れる)という結果が出ていました。しかしながら,こうした語彙的サポートがない複数形名詞の処理で反応時間が遅れるのかということは実験されていませんでした。私は,それをやって初めて,複数形の形態素をどう処理しているのかがわかるのではないか?と考えて,今回のような実験をするに至りました。だって,「単数形名詞 vs. 複数の絵」の条件では,実際には言語として複数形名詞を処理していないわけですから。
英文が表している空間的な位置関係は正しいが,名詞の単数・複数に違いがあり,その時に,この「数の違い」に反応して,「あれ?数が違うぞ?」となって反応時間が遅れるかどうかというところがポイントです。オリジナル研究のJiang et al. (2017)では,「位置関係だけに着目して「絵と英文がマッチしているかどうか」を判断するように求められていました。
結果として,Jiang et al. (2017)では学習者群で反応時間の遅れが見られなかった(a)の条件で反応時間の遅れが見られたんですよね。ところが,(b)の条件では遅れが見られなかったのです。この結果をどう解釈するのかというのが結構難しくて,最終的に意味的有標性という概念を使いました。これは博論でも使っています。
最近はRT(not retweet but reaction time)使う分析しかしていないので,ロジスティック回帰はやっていませんが(…とまで書いて,共著でロジスティック回帰使っている研究が先日リジェクトされたことを思い出したんですが),この論文のRコードのアップデートはなかなか難しそうなので,ロジスティック回帰やってる論文が出たらそのときはおそらくRのコードとデータも当然公開すると思いますので,そちらでご勘弁ください。
L2英語学習者が英語母語話者のように効率性を重視した数の一致処理を行っているかどうかについてを検討した論文で,Tamura et al. (2021)の追研究の位置づけです。Tamura et al. (2021)では,L2英語学習者は母語話者と違って,there | is/are | a | cat | and | とandを読んだ際に,複数一致の文(e.g., there are a cat and….)の読みが早くなる傾向が見られることを明らかにしました。そして,それは”A and B”のような等位接続名詞句は常に複数であるという明示的な知識の影響である可能性を指摘しました。今回は1つ目の実験で,there is/are |a cat and a dog| behind the sofa.のようにフレーズ単位での自己ペース読み課題を行い,単語単位の呈示ではなくフレーズ全体として等位接続名詞句をどう処理しているかを調査しました。結果として,やはりL2学習者は複数の読みが早くなることが明らかになり,there構文内の等位接続詞を複数として処理していることがわかりました。2つ目の実験ではTamura et al. (2021)同様に再度単語単位呈示での自己ペース読み課題を行いました。Tamura et al. (2021)では呈示順の影響が考慮されていなかったためです。例えば,andの後ろも名詞句が後続するとは限りません(e.g., there is a pen and it is broken)し,理論的にも,数の一致を再解釈する可能性があるとすれば2つ目の名詞句を処理した際であると仮定されています。したがって,Tamura et al. (2021)でandの時点で複数の読みが早くなった原因は,実験中にthere構文内に等位接続名詞句が生起する刺激文に晒されたことで複数一致の読みを予測するようになったからかもしれないからです。2つ目の実験の結果,there | is/are | a | catの段階では複数一致で遅れがみられ,直近の一致は単数で行う効率優先の処理が行われている可能性が示唆されました。ところが,この影響は実験が進むにつれて薄れていき,逆に実験が進むにつれて2つ目の名詞の領域で複数読み条件の読解時間が早くなる傾向があることが明らかになりました。これらの結果から,直近の動詞と名詞で数の一致を完結させる効率駆動型処理はL2英語学習者にも利用可能であることが示唆されました。しかしながら,2つ目の名詞句で一致を再解釈し直す現象はL2英語学習者に特有の現象であり,この原因として実験中に等位接続名詞句が埋め込まれたthere構文のインプットを受けることによって学習者の持つ等位接続名詞句は常に複数であるという明示的な知識が活性化され,それが言語処理に影響している可能性を指摘しました。
実は,このJournal of Psycholinguistic Researchに載った論文は,国内の学会紀要で不採択となったものです。国内の査読のほうが厳しいのだなと勉強になりました。院生時代に,「落ちたら国際誌」というブログ記事を書いたことがあり,まさか自分がそういうことをする日がくるとは当時は思っていませんでした。普通,まずはチャレンジとして国際誌に論文を投稿し,不採択であったら,国際誌よりも通りやすいであろうとおそらく多くの人が思うであろう国内の学会紀要に出すと思います。その逆(国内落ちたら国際誌)は私の敬愛する福田パイセンくらいしか例を知りません(経験者の方いたらQuerie.meで教えて下さい)。ちなみに,私がブログ記事を書くきっかけになったのはある後輩の発言なのですが,その時は普通に国内誌に通ったので結果として「落ちたら国際誌」にはなりませんでした。
査読で不採択となるというのはそれ相応の理由があり,今回のケースも通らなかったことについては自分自身でも納得しています。査読のプロセスでいただいたコメントを元に加筆した部分も多くありますが,決定的な理由を改善する事はできなかったのでそこについては「ママ」で再投稿しました。Journal of Psycholinguistic Researchはそんなに査読が厳しくないので,それで通ってしまったという感じです。個人的にも,この論文がそこまで面白いとも自信があるとも思っていないですが(そういうのは一生かかっても書けないと思っています),とりあえず,出版されたこと自体についてはホッとしています。2019年にとった研究費の研究で,「成果」を必ず出さなければならず,論文がなかなか出ずに事務の方に毎年催促されていたので…。
採択後の校正からオンライン公開までのプロセスがめちゃくちゃ早くてびっくりしたのですが,Journal of Psycholinguistic Researchの論文はしょっちゅうCorrectionが出ているイメージなので,ちょっと不安もありつつ,ツイッターで共有してくださっている方も何人かいらっしゃってありがたい気持ちです。
Investigation of the Relationship Between Animacy and L2 Learners’ Acquisition of the English Plural Morpheme | SpringerLink https://t.co/r1vqMW5WlX
Tamura, Y. (2022). Investigation of the Relationship Between Animacy and L2 Learners’ Acquisition of the English Plural Morpheme | SpringerLink https://t.co/mIsZqfkxzL
こちらはオープンアクセスになっていますので,どなたでも無料でお読みいただけます。Journal of Second Language Studiesは割と新しいジャーナルですが,このジャーナルで現在の”Most Read This Month”の論文となっています。個人的にはこれはめちゃくちゃ尖っていて多くの人に読まれてほしいやつですので,上の2つの論文よりはこちらをお読みください(余談ですが偶然にも”Most Cited”は私と福田パイセンの博士課程時代の指導教官である山下先生の論文です)。
a. As the mother and the father battled the child played the guitar in the room.
b. As the parents battled the child played the guitar in the room.
c. As the mother and the father left the child played the guitar in the room.
d. As the parents left the child played the guitar in the room.
battleのような相互作用動詞が目的語を取らないという解釈にいたるためには,主語が複数である必要があります。その時には相互作用動詞の後ろの名詞句は主節の主語として解釈され,ガーデンパスを回避できるということです。4条件作っているのは,(a) A and B(conjoined NP)とthe parentsのようなplural definite descriptionを比較したこと,(b) 動詞のバイアスの影響ではないことを示すために自動詞と他動詞の両方が解釈として可能な動詞の条件も用意し,その場合にはガーデンパスを回避することができないことを示す必要がある,という2点が理由です。
まず,Bilingualism: Language and Cognitionに出しました。そこでは,査読に回る前に,「母語話者と比較してないからだめ」という理由で突っぱねられましたが,「母語話者のデータがなくともこの実験の結果のみで十分に価値がある」という長めのメールを送り,いくつかの修正条件を提示されたのでその修正をし,最初の投稿から1ヶ月後くらいに再投稿しました。査読に周り,再投稿時点から2ヶ月たってreject通知をもらいました。とにかく,コメントの鋭さが今までに経験したことのないもので,すごくショックを感じるとともに,これをもとに修正したらもっと良くなるに違いないとも思えました。
二回目の投稿
大幅な書き直しが必要で,イントロ,バックグラウンド,ディスカッションとほぼすべて書き換えました。そして,2017年2月に今度はLinguistic Approaches to Bilingualismというところに出しました。外部査読に回るまでが1ヶ月,外部査読に回ってからは3ヶ月で結果が来たので,投稿から最初の結果がわかるまでは4ヶ月でした。そして,またrejectでした。
Studies in Second Language Acquisition(SSLA)に,ANOVAじゃなくて回帰やろうぜ?っていう論文が出ていた。著者はL2の効果量の大中小基準作ったったぜ論文で有名なPlonsky and Oswaldだ。
Plonsky, L., & Oswald, F. L. (2016). Multiple regression as a flexible alternative to ANOVA in L2 research. Studies in Second Language Acquisition. Advance Online Publication. doi:10.1017/S0272263116000231