Shiny Appsで遊ぶシリーズ第2弾。第1弾は以下でした。
今回は,もっと単純に,名前の列を入力したらそれをランダムに並び替える,というだけです。発表順をランダムに決めるとか,議事録担当者をランダムに決めるとか,様々な場面でご利用いただけます。
https://yutamura.shinyapps.io/RandomOrder/
なにをゆう たむらゆう。
おしまい。

Shiny Appsで遊ぶシリーズ第2弾。第1弾は以下でした。
今回は,もっと単純に,名前の列を入力したらそれをランダムに並び替える,というだけです。発表順をランダムに決めるとか,議事録担当者をランダムに決めるとか,様々な場面でご利用いただけます。
https://yutamura.shinyapps.io/RandomOrder/
なにをゆう たむらゆう。
おしまい。

タイトルのとおりです。Rmarkdownをknitしたとき,ファイル名に日付を入れたい場合にどうするかというお話。自分用メモです。
ファイルの中身の日付は,YAMLヘッダーをいじることで対応可能です。
参考:自動で日付を変更する R markdown tips https://qiita.com/masato-terai/items/50afd48ad741aa8b7bb6
今回は,knitした際に生成されたWordやHTMLのファイルに日付をいれたいので,上記の話とはちょっと違います。
私が調べた感じだと,YAMLヘッダーの指定でファイル名に日付をいれるのは無理そうでした(ChatGPTはいけるって感じで説明してきましたが,そのやり方でやってもだめでした)。そこで,rmarkdown::render関数の中のoutput_fileの引数で明示的に日付を指定してあげるという方法をとります。下記のような感じです。
rmarkdown::render("Experiment1_Analysis.Rmd", output_file = paste0("Experiment1_", Sys.Date(), ".html"))指定するのは,
の3つのみです。2つ目のファイル名の部分に,”Sys.Date()”をいれて,paste0()でくっつけることで,最終的なファイルが上の例だと”Experiment1_2024-04-26.html”のようになります。knitボタンを使う代わりに上のコードを実行すると,ファイルが生成されます。
もちろん,YAMLヘッダー上で,”output:html”の指定は必要ですし,wordにするならwordにしないといけません。その部分の指定と,ファイル名の拡張子の指定が一致していないとおかしなことになると思います。
ちなみに,上のコード部分のRコードチャンクに”include=F, eval=F”等の指定をしてあげないと,最終的に出力されるファイルのなかにコードが残るので注意が必要です。
Rmarkdownからknitすると,基本的にファイル名=Rmarkdownのファイル名で,生成されたファイルのファイル名を自分で変えないと,基本的には上書きされてしまいます。よって,ログを残す意味でも日付を入れたいよねというのが動機でした。もちろん,同日内で何度もレンダリングすれば同じ日付で上書きされてしまいますので,その場合はSys.Date()ではなくSys.time()にする必要はあります。
以上,メモでした。
なにをゆう たむらゆう。
おしまい。

私って,授業でグループ・ディスカッションとかよくすることがあるんです。そのときに,ランダムにグループ分けをしています(そうしないほうがいいときもあるでしょうけど)。そこで,いつもは下記のサイトにあるRコードを使って,その場でRを回しています。
ただ,Rを開いて,コードと名前リストをコピペして,っていうのがやや面倒なんですよね。それから,クラスの人数を把握して,何グループ作ったら何人のグループがいくつできるのかとか,そういうのを瞬時に頭の中で計算できた試しがありません。ぱっとその場で計算の得意な学生に聞くこともあるのですが,ややもたつきます。そこで,機械にやらせちゃおう,というお話。
ChatGPTに,こういうのを作りたい,と相談してコードを書いてもらい,修正したい部分が出てきたらその都度コードを書き換えてもらいながら1時間位で作りました。
https://yutamura.shinyapps.io/RandomGroup
名前リストをコピペして貼り付けて,グループ数を調整したらグループ分けがされます。
こだわりポイントはこんな感じで,今いる人数を計算して,何人のグループがいくつできるのかを提案してくれることです。

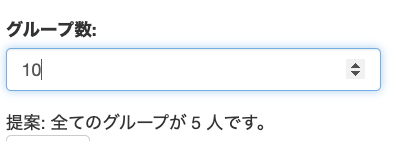
最初は,グループの数のあとに「つ」がついてたのですが,例えば,「5人のグループが10つできます」みたいな時が出てしまいます。数が二桁超えると「つ」はつかないですよね。もちろん,グループ数が多くなったら変えるみたいなロジックを追加することもできるっちゃできるわけですが,ちょっとめんどくさいなと思って(いや自分でコード書いてるわけじゃないんですけど),全部「個」にしました。「個」最強。ちょっと違和感あるにはありますけど。
100行まで名前リストを入力できるようにしているので,100人サイズのクラスまでは対応できるかなと思います。それより多くなったら2回に分けてもらう感じですかね。
インタラクティブな仕様にしたので,グループ数を変えていけば,その下の提案も変化して,自分で何人のグループがいくつにできるのかいくつか候補を見たうえでグループ分けができます(俺得)。
ChatGPTに,お試し用にコピペして使える名前リストを出してもらったので,このリストをコピペして実際にどんな感じか使ってみてください。
Alex Smith
Sam Johnson
Charlie Williams
Taylor Jones
Jordan Brown
Skyler Davis
Morgan Miller
Casey Wilson
Jamie Moore
Avery Taylor
Alex Smith
Sam Johnson
Charlie Williams
Taylor Jones
Jordan Brown
Skyler Davis
Morgan Miller
Casey Wilson
Jamie Moore
Avery Taylor
Alex Smith
Sam Johnson
Charlie Williams
Taylor Jones
Jordan Brown
Skyler Davis
Morgan Miller
Casey Wilson
Jamie Moore
Avery Taylor
Alex Smith
Sam Johnson
Charlie Williams
Taylor Jones
Jordan Brown
Skyler Davis
Morgan Miller
Casey Wilson
Jamie Moore
Avery Taylor
Alex Smith
Sam Johnson
Charlie Williams
Taylor Jones
Jordan Brown
Skyler Davis
Morgan Miller
Casey Wilson
Jamie Moore
Avery Taylor
※名前被ってたりして芸がない
いや,こんなことやってる場合じゃないんだ本当は…
なにをゆう たむらゆう
おしまい。

線形混合モデル(LME)・一般化線形混合モデル(GLMM)で,変量効果をデザイン上で最も複雑なものにする最大モデルを作って,それでだめなら切片と傾きの間の相関パラメータを除いたモデルにトライする,という提案(Bates et al., 2015)をやろうとするとき,相関を除くのは”||”(double-bar syntax)なんですが,単に”|”を”||”に変えるだけじゃうまくいかないのどうすんだろうなと思っていたら解決策が見つかったぽいというお話です。
ちなみに,この方法はdata-drivenで探索的な側面があり,best practiceというわけではありません。
具体的なコードとかは参考のところにも挙げたReduction of Complexity of Linear Mixed Models with Double-Bar Syntaxを見てください。
要するに,
m1 <- lmer (res ~ factorA + factorB + (1+factorA | ID), data =dat)みたいになってるとして,factorAが因子型だとするじゃないですか。そのときに,「相関を外そう」ということで
m2 <- lmer (res ~ factorA + factorB + (1+factorA || ID), data =dat)としてもうまくいかないよ,というお話です。これ,私もなんかうまくいかないなと思っていたんですが,解決策わからないので放置してました。「うまくいかない」というのはどういうことかというと,ただ単に”|”を”||”で置き換えるだけだと,切片とfactorAの第一水準(どういうコーディングしたかにもよりますけど)との相関パラメータは排除されるけれども,第一水準と第二水準の相関パラメータは残っちゃいますってことなんですね。でも,本当は全部の相関パラメータをなくしたいわけですね。
単純で,相関ありでfitさせたモデルの入った変数から,model.matrix()関数を使って変数名を直に取ってくる,ということです。m1という変数に相関ありのモデルが入ってるとすると,
model.matrix(m1)とやってみます。そうすると,モデルの中に入ってる変数の列がガーッと出てきます。その中で,自分が使いたい列名をモデル式にいれる,ということですね。例えば,factorAが事前,事後,遅延テストという3つの水準からなっているとすると,
pre_post <- model.matrix(m1)[,2] #列番号は適当です
pre_del <- model.matrix(m1)[,3] #列番号は適当ですみたいな感じで一旦変数に代入した上で,
m2 <- lmer (res ~ factorA + factorB + (1+ pre_post + pre_del || ID), data =dat)のようにさきほど代入した変数を使うと,”||”の指定によって相関パラメータがすべて除外されたモデルが作れるよ,ということのようです。
詳しくは下記の参考記事を御覧ください。lme4長いこと使ってますが,知らないことまだまだありますね…。
なにをゆう たむらゆう。
おしまい。
The Correlation Parameter in the Random Effects of Mixed Effects Models
Reduction of Complexity of Linear Mixed Models with Double-Bar Syntax

言語テスト学会の第26回(2023年度)全国研究大会(9/9-10 @ 東北大学)で下記のタイトルでワークショップをやります(私のWSは10日午前です)。
資料を準備している中で,私自身が最初にLME関係でウェブに上げた資料がslideshareにあり,それが有料版でないとダウンロードできないことに気づきました。そこで,その資料をそのままspeakerdeckにもアップロードしました。
2014年の資料なのでもう9年前になり,かなり古いですが,全く知らない人にとってはわかりやすいのかなと思います。
その後,2016年には下記のテクニカルレポートを書きました。
田村祐(2016)「外国語教育研究における二値データの分析-ロジスティック回帰を例に-」『外国語教育メディア学会中部支部外国語教育基礎研究部会2015年度報告論集』29–82. [リンク]
Rでロジスティック回帰をやる方法についてコードとともに解説したものです。このレポートをベースにしたワークショップも2019年に行いました。
そして,2021年にはこれまでに書いたり話したりしたものよりももう少し違う視点からの講演も行いました。
今回のワークショップは,2019年にやったロジスティック回帰がメインですが,もう少し「泥臭く」,実際に出版された次の論文のデータを使って,下処理のところからモデリングのところまでをやる予定です。
Terai, M., Fukuta, J., & Tamura, Y. (2023). Learnability of L2 collocations and L1 influence on L2 collocational representations of Japanese learners of English. International Review of Applied Linguistics in Language Teaching. https://doi.org/10.1515/iral-2022-0234
この論文のデータはOSFで公開されているものですので,どなたでもアクセスできます。
Terai, M., Fukuta, J., & Tamura, Y. (2023, June 7). Learnability of L2 Collocations and L1 Influence on L2 Collocational Representations of Japanese Learners of English. https://doi.org/10.17605/OSF.IO/ZQE56
この研究の分析ではカテゴリカル変数は使っていないのですが,カテゴリカル変数も扱いたいなと思ったので,データは Terai et al. (2023)ですが,論文中に行っている分析とは異なる分析をする予定です。
当日使用する資料は下記のページにまとめています(当日ギリギリまで投影資料は微修正すると思います)。
https://github.com/tam07pb915/JLTA_2023_WS
投影資料を直接ウェブでご覧になりたい方は,下記のURLで投影資料をご覧いただけます。
https://tam07pb915.github.io/JLTA_2023_WS/
一応前半は理論編,後半は実践編となっていて,Rのコードをアウトプットに文章の解説を入れています。ごちゃごちゃして見にくいかもしれませんがご容赦ください。
今回のWSは3時間ですが,たぶんそれだけでは消化不良になると思うので,私が過去に公開している他の資料と合わせて読んでいただくと良いのではと思います。
統計関係の話は専門家ではないのですが定期的にお声がけいただき,そのたびに勉強し(なおし)ているような気がします。
仙台までお越しになれないという方も,学会ウェブサイトにて動画が後日公開されるようですので,そちらをご覧いただければと思います。また動画が公開されましたらこのブログ記事にも追記します。
なにをゆう たむらゆう。
おしまい。
動画が公開されたようです。前後半に分かれています。
むかしむかし,D2のときに,下記のテクニカルレポートを出しました。
田村祐(2016)「外国語教育研究における二値データの分析-ロジスティック回帰を例に-」『外国語教育メディア学会中部支部外国語教育基礎研究部会2015年度報告論集』29–82.
外国語教育研究って,二値データを扱うことが結構多いのにそれを全部割合だったりに変換して線形モデル使ってるけど,ロジスティック回帰したほうがよくないですか?という話を,Rのコードとサンプルデータとともに分析の流れを紹介したものです。
当時はまだまだコードとデータを共有するというのが一般的ではなく,researchmapの「資料公開」という場所にデータとコードを置いて,そのリンクをbit.lyをかませて論文中の附録としてつけて,読者が実際にコードを走らせながら分析を学べるようにしていました。とはいっても,私は統計の専門家ではないので,当時自分が学んだことをまとめたかったことと,分析の相談を受けた際に「これ読めばできます」と言って済ませたかったのでした。
最近,知り合いから,リンクが死んでるんだけど,どっかに移した?みたいな連絡を受けて,そんなはずはないけどなと思って確かめてみると,確かに論文中のリンクからはアクセスできなくなってしまいました。おそらくですが,researchmapの仕様変更でURLが変わってしまったためかと思われます。それはちょっとまずいなと思い,コードとデータをOSFに移行し,そちらのリンクを論文中に貼り付けたものを訂正版として,編集委員長にお願いして訂正版のPDFを公開してもらいました(bit.lyのリンク修正は有料でないとできなかったので断念。またOSFのほうが利便性高そうなので)。一応もとのPDFにもアクセス可能です。編集委員長様,迅速な対応ありがとうございました。
7年も前のコードで(D2が7年前という衝撃),当時学びたてだったdplyrなんかは今と書き方が異なる部分も多いので,おそらく今の環境では動かなくなってしまっているコードも結構あるのではと思いますが,それも全部書き直すだけの余裕はちょっとなかったので,それはしていません。ただ,読み直していたら表番号の参照がずれているのに気づき,それは直した上で後ろに正誤表をつけました。
何年ぶりかにファイルを開いたら,Word上での見た目がなぜか公開されているPDFファイルの見た目と異なり,ページの設定は同じはずなのに行送りが微妙にずれていたりして若干もとの論文とページ数が異なる箇所がありますが,内容は変わっていません。researchmapを見ると,コードは300件以上,論文中のサンプルスタディ1は600件以上のダウンロードがあり(この差はなんで?),LET中部のサイト上にある論文PDF自体も400件近くダウンロードされています。
おそらくですが,附録のリンクが機能せず,「なんやねん!しばくぞボケ!」ってなった方も100人くらいはいらっしゃるのではないかと思います。申し訳ありません。データとコードは私のresearchmapの「資料公開」にあります。また,OSFは以下のURLです(余談ですが,researchmapはURLに日本語が含まれているのでそれまじでやめてほしい)。
https://doi.org/10.17605/OSF.IO/2FS9B
別に引用はされないですけれども(そもそもこの論文が引用されていても通知も来ないしわからないと思います),今でも閲覧しようと思う人(まあ知り合いなんですが)がいるというのは,あのとき頑張ってよかったなぁとなんとなく思います。時間があったからできたことではあるのですけれど。
最近はRT(not retweet but reaction time)使う分析しかしていないので,ロジスティック回帰はやっていませんが(…とまで書いて,共著でロジスティック回帰使っている研究が先日リジェクトされたことを思い出したんですが),この論文のRコードのアップデートはなかなか難しそうなので,ロジスティック回帰やってる論文が出たらそのときはおそらくRのコードとデータも当然公開すると思いますので,そちらでご勘弁ください。
LET中部支部は新しいウェブサイト(https://letchubu.org/)が動いているので,いずれ今の基礎研論集のページのURLも変わったりするのかなと思いつつ,これ全部移行するの業務委託とかじゃなく誰かがやるのだとしたら100万くらいもらっていいのではと思ったり(LET関西支部もウェブサイト再構築検討中ですが委託です)。
なにをゆう たむらゆう。
おしまい。

dplyr使いの方で,select関数を使って特定の1列に対して何かしらの処理をするということをしたいときにエラーが出る人はpull関数を使いましょうという話です。ちなみに,$使えば問題は解決です。今回は,それ以外の方法で,というお話。
私がどんな処理をしようとしたかについて少し触れておきます。ここはスキップしてもらっても構いません。
ある列の単語(1単語または2単語の英単語が入っている)の文字数をカウントするということをやろうとしていました。ピリオドが含まれていたり(e.g., “dogs.”),2語の場合は間に空白もあるので(e.g., “beautiful lake”,それらを除去して文字数を数える必要があります。そのためには,str_extract,str_replace, str_lengthなどの文字列処理関数を使う必要があります。しかし,これらの関数はベクトルを受け取って処理をするので,データフレームを渡してもエラーが出てしまうという問題に直面しました。
データフレームからある特定の列を引っ張ってくるというとき,もちろん$を使って,dat$wordのようにするのが一番簡単なのでそれでもいいのですけども,dplyr使いの方はselect関数を使っている方も多いのではと思います。ただし,select関数はデータフレームの中から特定の列を引っ張ってくると,それがたとえ1列であってもdata.frame型になります。
よって,処理に使う関数がベクトル型を要求するものだとエラーが発生することになるわけです。しかもやっかいなのは,「じゃあas.vector()関数」を噛ませればいいやんとやってみてもそれでは解決しないからです。理由はよくわかりません。
dat %>%
select(word) %>% #wordという列に文字数カウントしたい文字列があるとする
as.vector() %>%
is.vector() #このコードではFALSEとなります
pull関数は,要するにdat$x1のように$を使って,またはdat[, x1]のように[,]を使ってデータフレームの中の特定の列を指定するのと同じ挙動をするということです(参考)。よって,pull関数の出力はベクトル型になります。
dat %>%
pull(word) %>%
is.vector() #このコードではTRUEとなります
というわけで,1列だけ持ってくるときに関数を使う場合はpull()関数を使いましょうというのが結論です。私は結局こういう感じで文字数カウントをしました。
dat %>%
pull(word) %>%
str_extract(.,"[^\\.]+") %>% #ピリオドを除去
str_replace(.,pattern = "\\s",replacement = "") %>% #半角スペースを除去
str_length()->rt_dat$length #文字数をカウント
$を使うと次のようになります。
str_extract(dat$word,"[^\\.]+") %>% #ピリオドを除去
str_replace(.,pattern = "\\s",replacement = "") %>% #半角スペースを除去
str_length()-> dat$length #文字数をカウントしてlengthという列に入れる
$を使ったほうが行数が少なくなるので,そっちのほうがいいような気もしますが,工程の見やすさでいうとpull関数を使うほうが上かなという感じがします。
もともと文字数はカウントしてあったのですが,ちょっと査読者の指摘でフィラー項目も入れて分析をやり直さないといけなくなってこういった処理が必要になりました。データ型って基本といえば基本なのですが,以外に気づかずにエラーで困ることもあるので,select関数の挙動について勉強になるいい機会でした。
ということで,pull関数とselect関数,場合によって使い分けましょう。
なにをゆう たむらゆう。
おしまい。
以前,下記のようなブログ記事を書きました。
一言で言えば,教師側で作ったテンプレファイルをフォルダごと学生と共有し,学生は自分の名前のついているWordファイル上で執筆活動を行い,教師側はリアルタイムでその進捗をモニタしつつフィードバックを出していくというようなライティング授業実践です。
今年度からは3年次のライティング授業も持っていて,その授業ではペアでのcollaborative writingも取り入れています。最初はペアはこちらで作ってファイルは学生に作らせてリンクを教師と共有という形でやっていましたが,それだとやっぱり使い勝手が悪い(教師側が自分のローカルからファイル閲覧できないとか他にも色々問題ががが)というのがあって,やっぱり教師が学生のファイルを作るほうがいいだろうという結論に至りました。
これは昔知り合いの川口先生がブログ記事に書いていたような気がするなと調べたらすぐ見つかったので,そこの記事で紹介されているものをそのまま使いました。
上記ブログ記事先のやり方でやると,リスト形式で学生のペアリングリストが手に入ります。ただし,それをファイル名に転用できるようにしようとするとひと手間工夫が必要です。リストのそれぞれの要素に入っているクォーテーションマークでくくられた名前を結合して1つにまとめる必要があるからです。
私がもともとやっていたのは,文字列ベクトルの1つ目から順番にとってきて,それをファイル名にするというものでした。今回はペアですので2人(もし奇数なら3人組もできる)の名前を1つのファイル名にしようということになります。
リスト内の要素を結合するには次のようにします。
sapply(pairing,paste,collapse="&")->pairing2
pairingがリスト形式のグループ分けです。最終的にpairing2という変数には
"TAMURA Yu&KAWAGUCHI Yusaku" "TERAI Masato&FUKUTA Junya"
といったように名前が&でつながれた文字列のベクトルが入っています。あとはテンプレファイル複製のやり方と同じです。
setwd(here("Week9&10"));getwd() #Create a folder before runnning this code
dirnow <-getwd()
list1<-list.files()
print(list1)
original<-file.path(dirnow,list1) #Use the original file name
filename1<-paste(pairing2,list1,sep="_")
print(filename1) #Check all the file names
for (i in 1:length(filename1)){
file.copy(from=original,to=paste(dirnow,filename1[i],sep="/"))
}
list.files()
私は”rename”というフォルダ内にその週の課題ファイルを入れるフォルダを作っています。そのrenameという場所にRStudioがあるので,そこがワーキングディレクトリとなっています。それをその1つ下の階層に移してあげるのが1行目です。”Week9&10″というのがフォルダ名ということですね。そこに, “2022_Spring_AW_Week9&10.docx”という名前のテンプレファイルが1つはいっています。
3,4行目はそのコピー元ファイルがちゃんとあることの確認ですね。6行目でペアリングされた学生の名前が&で結ばれたものと,テンプレファイル名をアンダーバーでくっつけています。こうすることで,filename1という変数内には,
"TAMURA Yu&KAWAGUCHI Yusaku_2022_Spring_AW_Week9&10.docx" "TERAI Masato&FUKUTA Junya_2022_Spring_AW_Week9&10.docx"
のような最終的に変換されるファイル名が入ります。あとはfor関数の中でfile.copy関数を使ってファイルを複製し,そのときのファイル名をさきほど作ったfilename1の1番から最後までにしてあげるということになっています。
最後に元のテンプレファイルをフォルダから削除し,renameフォルダ内から”Week9&10″をひとつ上の階層(私の場合授業のフォルダ)にあげてからフォルダごと共有リンクをLMSに貼ればOKです。学生側はフォルダにアクセスし,自分の名前が入ったファイル上でペアと一緒にライティングをしていくことになります。
もしも,ペアリングは自動ではなく手動でやりたいという場合は,エクセルなんかで2列になったものをコピーして,pairing変数にいれてあげればあとは同じようにできると思います。
このRのルーティンを作るのに調べ物とかも含めて1時間くらいかかりました。そこで気づいたのですが,自分の担当しているのクラスは12人という少クラスで6ペアしかできないので,こんなことしなくても手作業複製とファイル名変更したほうが作業効率がよかったのではないか…という。
もっと大人数のクラスでcollaborative writingをやろうと思っていて,でもファイル管理がめんどくさい…という方の助けになれば。
なにをゆう たむらゆう。
おしまい。

以前(というかかなり昔),tidyrやdplyrについての記事を書きました。
どちらの記事を書いたときからもだいぶ月日が経っていて,dplyrのアップデート等もあって色々とやり方が変わっているのですが,自分自身が研究で分析をする際にアップデートしていたことをブログ記事には反映させられていないので,上の2本の記事のアップデート版のようなことを書いておこうと思います。
#事前・事後・遅延事後でCAFのデータを取ってるというデザイン
pre.fluency <-rnorm(50,mean=10,sd=2)
pre.accuracy<-rnorm(50,mean=7,sd=2)
pre.complexity<-rnorm(50,mean=4,sd=2)
post.fluency<-rnorm(50,mean=14,sd=4)
post.accuracy<-rnorm(50,mean=10,sd=3)
post.complexity<-rnorm(50,mean=7,sd=2)
delayed.fluency<-rnorm(50,mean=12,sd=2)
delayed.accuracy<-rnorm(50,mean=8,sd=1)
delayed.complexity<-rnorm(50,mean=6,sd=1)
#それぞれの列を横にくっつける
dat<-cbind(pre.fluency,pre.accuracy,pre.complexity,post.fluency,post.accuracy,post.complexity,delayed.fluency,delayed.accuracy,delayed.complexity)
dat<-as.data.frame(dat) #データフレーム型に変換
dat$subject<-rep(1:50) #実験参与者のID列をつけるhead(dat)## pre.fluency pre.accuracy pre.complexity post.fluency post.accuracy
## 1 9.344978 3.921626 4.5778491 13.932376 2.241629
## 2 9.126920 7.307178 3.2309289 13.624622 12.813440
## 3 13.433524 6.048270 5.0082008 7.932601 11.832851
## 4 11.937755 5.859142 0.6414096 11.289177 7.009059
## 5 7.913083 5.748651 2.6099159 17.933721 10.765706
## 6 8.683515 4.363661 5.4608116 16.550468 16.483160
## post.complexity delayed.fluency delayed.accuracy delayed.complexity subject
## 1 9.381369 10.628923 6.929672 7.923673 1
## 2 4.485729 14.456886 9.048825 5.306266 2
## 3 7.534226 13.031400 7.144670 7.781451 3
## 4 8.076248 12.390157 9.247418 6.244443 4
## 5 8.702016 9.604130 7.530200 5.927892 5
## 6 8.973912 8.060271 8.188526 6.458383 6昔の縦横変換は,gatherでやっていました。現在は,pivot_関数を使います。その名の通り,縦長(long型)にするのがpivot_longer関数で,横長にするのがpivot_wider関数です。
library(dplyr)
dat %>%
tidyr::pivot_longer(cols = 1:9)## # A tibble: 450 × 3
## subject name value
## <int> <chr> <dbl>
## 1 1 pre.fluency 9.34
## 2 1 pre.accuracy 3.92
## 3 1 pre.complexity 4.58
## 4 1 post.fluency 13.9
## 5 1 post.accuracy 2.24
## 6 1 post.complexity 9.38
## 7 1 delayed.fluency 10.6
## 8 1 delayed.accuracy 6.93
## 9 1 delayed.complexity 7.92
## 10 2 pre.fluency 9.13
## # … with 440 more rowscolsのところでどの列をまとめるかという指定をします。ここの指定は,上のやり方だと数字で列指定(1列目から9列目)としています。この部分はc()関数を使って文字列で指定してもいいですし,列指定のときに使えるstarts_with()やcontains() なんかもできます。例えば,まあこれはあくまで偶然そうなだけですけど,ここではまとめたい1列目から9列目はすべて”y”で終わっているので,以下のようにすることもできます。
dat %>%
tidyr::pivot_longer(cols = ends_with("y"))## # A tibble: 450 × 3
## subject name value
## <int> <chr> <dbl>
## 1 1 pre.fluency 9.34
## 2 1 pre.accuracy 3.92
## 3 1 pre.complexity 4.58
## 4 1 post.fluency 13.9
## 5 1 post.accuracy 2.24
## 6 1 post.complexity 9.38
## 7 1 delayed.fluency 10.6
## 8 1 delayed.accuracy 6.93
## 9 1 delayed.complexity 7.92
## 10 2 pre.fluency 9.13
## # … with 440 more rowsまた,まとめたくない列を”!“で指定することもできるので,今回のようにまとめないでほしい列が少ないという場合については,次のようにも出来ます。
dat %>%
tidyr::pivot_longer(!subject)## # A tibble: 450 × 3
## subject name value
## <int> <chr> <dbl>
## 1 1 pre.fluency 9.34
## 2 1 pre.accuracy 3.92
## 3 1 pre.complexity 4.58
## 4 1 post.fluency 13.9
## 5 1 post.accuracy 2.24
## 6 1 post.complexity 9.38
## 7 1 delayed.fluency 10.6
## 8 1 delayed.accuracy 6.93
## 9 1 delayed.complexity 7.92
## 10 2 pre.fluency 9.13
## # … with 440 more rows「まとめる」という感覚がいまいちよくわからないなぁとか,どの列を「まとめ」て,どの列は「まとめ」なくていいのかというのがピンと来ない場合には,次のように考えてください。
分析の際に従属変数(応答変数)となる列をまとめる
さて,今の段階ではまとめた際の列名が”name”になっていて,数値の部分が”value”という列名になっていますよね。ここも次のように指定できます。
dat %>%
tidyr::pivot_longer(!subject, names_to = "variable", values_to = "score")## # A tibble: 450 × 3
## subject variable score
## <int> <chr> <dbl>
## 1 1 pre.fluency 9.34
## 2 1 pre.accuracy 3.92
## 3 1 pre.complexity 4.58
## 4 1 post.fluency 13.9
## 5 1 post.accuracy 2.24
## 6 1 post.complexity 9.38
## 7 1 delayed.fluency 10.6
## 8 1 delayed.accuracy 6.93
## 9 1 delayed.complexity 7.92
## 10 2 pre.fluency 9.13
## # … with 440 more rowsただ,今回のケースではまとめた列に”pre”, “post”, “delayed”というテスト実施時期(test)という要因と,“complexity”, “accuracy”, “fluency”という測定値の要因が混在していますね。よって,あまり”name”の列名を変えることは意味がありません。むしろ,この列を分割してそれぞれの列に名前をつける必要があります。この列分割をseparate関数で行うという点は私が以前ブログ記事を書いた際と同じです。というわけで,次のようにします。
dat %>%
tidyr::pivot_longer(!subject) %>%
tidyr::separate(name, c("test","measure"), sep = "\\.")## # A tibble: 450 × 4
## subject test measure value
## <int> <chr> <chr> <dbl>
## 1 1 pre fluency 9.34
## 2 1 pre accuracy 3.92
## 3 1 pre complexity 4.58
## 4 1 post fluency 13.9
## 5 1 post accuracy 2.24
## 6 1 post complexity 9.38
## 7 1 delayed fluency 10.6
## 8 1 delayed accuracy 6.93
## 9 1 delayed complexity 7.92
## 10 2 pre fluency 9.13
## # … with 440 more rowsこれで,完璧ですね。と思いきや…!実はpivot_関数には”name_sep”という便利な引数があります。これはどういう時に使うかと言うと,まとめた際に一つの列に複数の要因が混在してしまうときに,それを指定した区切り文字によって分割するために使います。まさに上で起こった問題ですよね。テスト実施時期と測定値が一緒の列になっていたのをseparate関数で分割したわけですが,なんとseparateを使わなくても縦型に変換する段階で分割までできてしまいます。
dat %>%
tidyr::pivot_longer(!subject, names_to = c("test", "measure"), names_sep = "\\.", values_to = "score")## # A tibble: 450 × 4
## subject test measure score
## <int> <chr> <chr> <dbl>
## 1 1 pre fluency 9.34
## 2 1 pre accuracy 3.92
## 3 1 pre complexity 4.58
## 4 1 post fluency 13.9
## 5 1 post accuracy 2.24
## 6 1 post complexity 9.38
## 7 1 delayed fluency 10.6
## 8 1 delayed accuracy 6.93
## 9 1 delayed complexity 7.92
## 10 2 pre fluency 9.13
## # … with 440 more rowsこのときのポイントは2点あります。1つは”names_to”で列名を2つ指定すること。縦型変換の際に列の分割もするので,ここでのnames_toの指定は分割後の列名とします。もう一つは,区切り文字は正規表現を受け付けるということ。区切り文字がドット(.)なので,ここでnames_sep= “.”としてしまうと,正規表現におけるドットだと認識されてしまいます。これでは任意の1文字ですので,列名がうまく分割されずに以下のようになってしまいます。
dat %>%
tidyr::pivot_longer(!subject, names_to = c("test", "measure"), names_sep = ".", values_to = "score")## Warning: Expected 2 pieces. Additional pieces discarded in 9 rows [1, 2, 3, 4,
## 5, 6, 7, 8, 9].## # A tibble: 450 × 4
## subject test measure score
## <int> <chr> <chr> <dbl>
## 1 1 "" "" 9.34
## 2 1 "" "" 3.92
## 3 1 "" "" 4.58
## 4 1 "" "" 13.9
## 5 1 "" "" 2.24
## 6 1 "" "" 9.38
## 7 1 "" "" 10.6
## 8 1 "" "" 6.93
## 9 1 "" "" 7.92
## 10 2 "" "" 9.13
## # … with 440 more rowsしたがって,正規表現ではありませんよということを追記する必要があります。このことをエスケープするなんて言いますが,Rにおけるエスケープは “\\”です。一般的にはエスケープは”\“ですが,R上では2つ重ねないといけないことに注意が必要です。
とりあえず,long型に変換する作業をこの記事では説明しました。少し長くなってしまったので,記述統計を出すという話はまた別の記事にしたいと思います。
なにをゆう たむらゆう。
おしまい。
よく考えたら,分析するときはcomplexity, accuracy, fluencyの3つの列があったほうが便利ですよね。ということで,その形に変形させましょう。ここで,横長に変換するためのpivot_wider関数を使います。“names_from”の引数で「分解」したい列を指定します。ここでは,accuracy, complexity, fluencyの入っている“measure”の列を「分解」して横長にするので,“measure”を指定します。あとは,横長にしたときに持ってくる数値がどこに入っているかを“values_from”の引数で指定します。これは“score”に入ってますから,これを指定すればいいですね。というわけで,次のようになります。
dat %>%
tidyr::pivot_longer(!subject, names_to = c("test", "measure"), names_sep = "\\.", values_to = "score") %>%
tidyr::pivot_wider(names_from = "measure", values_from="score")## # A tibble: 150 × 5
## subject test fluency accuracy complexity
## <int> <chr> <dbl> <dbl> <dbl>
## 1 1 pre 10.1 10.0 3.97
## 2 1 post 15.8 8.50 9.81
## 3 1 delayed 15.5 8.59 4.67
## 4 2 pre 12.0 6.40 1.03
## 5 2 post 6.90 10.1 7.30
## 6 2 delayed 15.0 8.54 7.70
## 7 3 pre 9.07 8.49 2.78
## 8 3 post 7.11 10.2 8.55
## 9 3 delayed 10.7 7.97 5.54
## 10 4 pre 12.5 6.03 2.26
## # … with 140 more rowsもしも,fluency, accuracy, complexityなどの順番が気になる場合は,select関数で指定してください。
dat %>%
tidyr::pivot_longer(!subject, names_to = c("test", "measure"), names_sep = "\\.", values_to = "score") %>%
tidyr::pivot_wider(names_from = "measure", values_from="score") %>%
dplyr::select(subject, test, complexity, accuracy, fluency)## # A tibble: 150 × 5
## subject test complexity accuracy fluency
## <int> <chr> <dbl> <dbl> <dbl>
## 1 1 pre 3.97 10.0 10.1
## 2 1 post 9.81 8.50 15.8
## 3 1 delayed 4.67 8.59 15.5
## 4 2 pre 1.03 6.40 12.0
## 5 2 post 7.30 10.1 6.90
## 6 2 delayed 7.70 8.54 15.0
## 7 3 pre 2.78 8.49 9.07
## 8 3 post 8.55 10.2 7.11
## 9 3 delayed 5.54 7.97 10.7
## 10 4 pre 2.26 6.03 12.5
## # … with 140 more rowsこの変換後のデータを別の変数に保存するのを忘れずに!
dat2 <- dat %>%
tidyr::pivot_longer(!subject, names_to = c("test", "measure"), names_sep = "\\.", values_to = "score") %>%
tidyr::pivot_wider(names_from = "measure", values_from="score") %>%
dplyr::select(subject, test, complexity, accuracy, fluency)
head(dat2)## # A tibble: 6 × 5
## subject test complexity accuracy fluency
## <int> <chr> <dbl> <dbl> <dbl>
## 1 1 pre 3.97 10.0 10.1
## 2 1 post 9.81 8.50 15.8
## 3 1 delayed 4.67 8.59 15.5
## 4 2 pre 1.03 6.40 12.0
## 5 2 post 7.30 10.1 6.90
## 6 2 delayed 7.70 8.54 15.0
2021年11月6日土曜日に,名古屋大学大学院人文学研究科英語教育分野主催の連続公開講座『データサイエンス時代の英語教育』(2)で『一般化線形混合モデルの実践 — 気をつけたい三つのポイント』というタイトルの講演をします。
名古屋大学大学院人文学研究科は私が所属していた研究科ではありませんが,大学院の再編があり私がお世話になった先生方が所属している研究科であり,私の後輩にあたる院生も人文学研究科に所属しています。そういう縁もあってお話をいただきました。私が統計の話をするというのはかなりハードルが高い(統計の専門家ではないですし知識と技術に自信があるわけでも正直ない)と思ったのですが,こういう機会をいただくことでまた自分の知識を更新し,さらにレベルアップする機会にもなると思ったので,お引き受けすることにしました。
フライヤーに要旨も載っていますが,私が名古屋大学大学院国際開発研究科博士後期課程に進学した2014年にNagoya.Rというイベントで『一般化線形混合モデル入門の入門』というタイトルで発表をしました。
ちょうど2012年に下記のレビュー論文が出ていて,それをもとにRでどうやってやるかというのをただただ紹介したみたいな感じでした。
Cunnings, I. (2012). An overview of mixed-effects statistical models for second language researchers. Second Language Research, 28(3), 369–382. https://doi.org/10.1177/0267658312443651
一般化線形混合モデルという発表タイトルでしたが,実際は一般化ではなく線形混合モデルのやり方で,私はその後の院生生活で,反応時間を扱う研究ではガンマ分布や逆正規分布,容認性判断のような二値データを扱うデータでは二項分布を使った一般化線形混合モデルを扱うようになっていきました。
7年前はそこまでウェブ上でも特に日本語では資料が多くなかったこともあり,分野を問わず上記のスライドシェアの資料は結構閲覧されていて,D2で学振の申請書を書いたときには「Googleで一般化線形混合モデルというキーワードで検索すると上に来るのは私の資料です」みたいなことを書いたこともありました(笑)
2016年にはおもにロジスティック回帰に焦点をあてたテクニカルレポートを書きました。
田村祐(2016)「外国語教育研究における二値データの分析-ロジスティック回帰を例に-」『外国語教育メディア学会中部支部外国語教育基礎研究部会2015年度報告論集』29–82. [リンク]
そして,このテクニカルレポートで書いた内容をもとにして2019年には統計のワークショップ講師をしたこともありました。
https://github.com/tam07pb915/JACET-SIG_GLMM-Workshop
そういった流れのなかで,一般化線形混合モデルのレビュー論文のようなものもいくつか新しく出版されているので,そうしたものをまとめた内容にしようと思っています。今回はワークショップではなく「講演」なので,ハンズオンで実際に分析ができるようになるということを目指すわけではなく,(1) 分析の方法,(2) 分析結果の報告,(3) 再現性の確保,という3つの観点から一般化線形混合モデルという分析の手法について話すつもりです。(3)の再現性については,昨今の再現可能性という問題を意識してのものであり,特にこの分析手法だけに当てはまるものではありません。ただ,自分が特に強い関心を持っているのであえて今回の話に盛り込むことにしました。特に,国内の学会紀要などはこういったデータ・マテリアルの公開・共有に関してガイドラインの設定がされていません。このことは今後の研究の発展を大きく阻害すると思いますので,そういったメッセージも入っています(資料はまだアウトライン程度しかできていませんが)。
資料ができたらこの記事の最後に資料へのリンクを追記する予定です。
参加申込は下記のURLから可能で,申込みの締め切りというのは特に設けられていないということです。
https://forms.gle/Ez4GmQC2JpS4j2R49
興味のある方はぜひご参加ください。よろしくお願いします。
なにをゆう たむらゆう。
おしまい。
2021.11.07 追記
当日の資料です。
