
はじめに
日本語を第一言語とする英語学習者の数の処理について,International Journal of Bilingualismから論文が出ました。
https://journals.sagepub.com/doi/10.1177/13670069261422017
Tamura, Y. (2026). Singular–plural asymmetry in L2 English number processing: A sentence-picture matching study of Japanese learners of English. International Journal of Bilingualism. https://doi.org/10.1177/13670069261422017
オープンアクセスですので,どなたでも全文ご覧いただけます。論文の要約は私の個人ウェブサイトに記事を書いたので,そちらを引用しておきます。
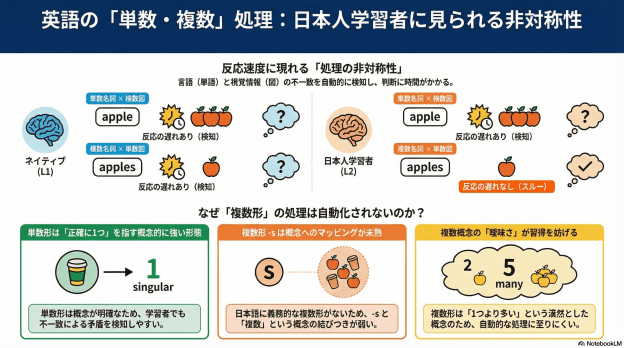
日本語を第一言語とする英語学習者が,英語の単数・複数形を文処理中に自動的に概念的意味へとマッピングできているかどうかを調べた研究です。
先行研究(Jiang et al., 2017)では,文中に単数形名詞が出てきたとき,それが複数の物が写っている写真とペアになると,母語話者の反応時間が遅くなることが示されていました。これは,文処理中に単数形の意味(=1つ)が自動的に活性化され,写真の内容との概念的な不一致が干渉を生んでいることを意味します。ただし,Jiang et al. の研究では「単数名詞×複数の写真」という一方向のミスマッチしか検討されていませんでした。では逆方向,つまり「複数形名詞×1つの物の写真」ではどうなのか,については誰も調べていなかったのです。
本研究では,文と写真のマッチング課題を用いて,この両方向のミスマッチを同時に検討しました。実験の仕掛けはこうです。まず参加者に写真(物が1つか3つ写っているもの)を見せ,続いて写真の内容(物の位置や色)を説明した英文を提示します。参加者は「文が写真を正しく説明しているか」をできるだけ速く判断します。肝心なのは,ターゲット試行では単数・複数のミスマッチが仕込まれていること,そして参加者には「数のズレは気にしないでいい」と明示的に教示している点です。それでも反応時間に遅れが生じるならば,数の処理は意識的な注意とは独立して自動的に行われている,ということになります。L1英語話者32名と日本語がL1の英語学習者96名を対象に実施し,反応時間データを逆ガウス分布の一般化線形混合モデルで分析しました。
結果として,L1英語話者は両方向のミスマッチで反応時間の遅れを示しました。単数名詞が複数の写真とペアになっても,複数形名詞が1つの物の写真とペアになっても,どちらも干渉が起きていたわけです。一方,L1日本語英語学習者は,単数名詞が複数写真とペアになった条件では反応時間の遅れが見られたものの,複数形名詞が1つの写真とペアになった条件では有意な遅れが見られませんでした。
この非対称性の説明として,本研究では意味的有標性(semantic markedness)の概念を援用しています。単数形の意味(=正確に1つ)は精確で特定性が高いのに対し,複数形の意味(=1より多い)は本来ぼんやりしていて,特定の数を指すわけではありません(Sauerland et al., 2005; Patson et al., 2014)。学習者にとっては,この「単数のクリアさ」があるからこそ自動的な概念マッピングが成立するが,「複数の意味のぼんやりさ」に加えて,日本語には義務的な複数形形態素が存在しないという母語の影響(Morphological Congruency Hypothesis; Jiang et al., 2011)も重なり,複数形と複数概念のリンクが自動化されるに至っていない,という解釈です。
この結果がとくに重要なのは,これまでの研究の解釈に修正を迫る点です。Tamura (2025)でも論じたように,先行研究で見られてきた学習者の複数形態素への「非敏感性」は,複数形を処理できていないとか意味が載っていないということを必ずしも意味しません。本研究の文脈では,単数形から複数形への方向ではきちんと干渉が生じていることから,問題は形式と意味のマッピングの有無ではなく,その自動化の度合いや方向性によって異なる,という可能性を示唆しています。両方向のミスマッチを一つの実験で検討したのは本研究が初めてであり,この非対称性を明らかにした点に独自の意義があると考えています。
https://tamurayu.wordpress.com/2026/02/27/tamura-2026/
出版に至るまでの裏話
最初は,元の研究になっているJiang et al. (2017)の追試研究として書きました。もともと博論を構成する研究のうちの一つだったのですが,そのときは実験2つを組み合わせた解釈をしてたから割といけたんですが,この実験だけ取り出して新規性とか議論を膨らませるのが結構難しくて,全然書き進められていなかったのが原因でした(5000語くらいでずっと塩漬けになっていました)。
そこで開き直って追試として論文書いたら,元研究との比較を軸にディスカッションできるなと思ったのです。ところがまあそれはリジェクトされてしまいまして。そのアプローチはうまくいかんかー。ということで,元々書いていた追試ではないオリジナルリサーチの方向でなんとか最後まで書き切って別のジャーナルに投稿しました。しかしそれもまた落ちまして。
どうするかーと悩んでいたところで,Jiang et al (2017)が掲載されているIJBに出そうかなと考えました。IJBは語数制限が厳しいので,イントロもコンパクトに,ディスカッションもコンパクトにという感じで,逆にそれがこの研究には良かったのかもしれません。
投稿したらエディターに,「うちはもうSLAの論文載せてないのよ〜バイリンガリズムとSLA研究は違う分野になっちゃったからさ」(大意)みたいなことを言われて,「まあでもconvince meしてくれたら査読回すよ」(大意)と言われたので「いやバイリンガリズムの観点からも意義ありまんがな」と必死にアピールして査読に回してもらい,査読自体は時間はかかりましたが,さほど査読プロセスは厳しくなくminor revision -> acceptとなりました。
この実験の着想
英語には,名詞の単数・複数を形で区別する仕組みがあります。この複数形形態素の習得というのは,簡単そうに見えて実は数の一致の誤りにはなかなか気づけないこともあるなど,第二言語習得研究の関心事でした。私の博士論文は,「数の一致」の誤りに気づけるかどうか,という,いわゆる誤文反応検知(anomaly detection)
先行研究(Jiang et al., 2017)では,「単数形の名詞と複数の絵を見せると,母語話者は処理が遅くなる」という結果が示されていました。つまり,頭の中で「あれ,合ってないぞ」という衝突が起きるわけです。
ところが,Jiang et al. (2017)では,「単数形名詞 vs. 複数の絵」という実験はありましたが,「複数形名詞 vs 1つの絵」(実験3)では常にseveralやtwo,manyのような語彙的な複数を表すマーカーが含まれていて,これがあると不一致条件で遅れが出る(例:several paper bagsと読んでbagが一つだけなら遅れる)という結果が出ていました。しかしながら,こうした語彙的サポートがない複数形名詞の処理で反応時間が遅れるのかということは実験されていませんでした。私は,それをやって初めて,複数形の形態素をどう処理しているのかがわかるのではないか?と考えて,今回のような実験をするに至りました。だって,「単数形名詞 vs. 複数の絵」の条件では,実際には言語として複数形名詞を処理していないわけですから。
リジェクトされた原因
2回のリジェクトの割と大きい理由のひとつは,元の研究と実験の手順を微妙に変えたことなんです。この課題の肝は,上の要約にも書きましたが,絵と英文の位置関係を判断する課題の中で,物体の数が異なったりしているという条件があることです。例えば,
(a)The red onion is right above the yellow cup.
という英文を読んで,でも実際に見えている画像には黄色いカップが3つあるという単数名詞不一致条件と,
(b)The birds are on the right side of the orange cups.
という英文を読んで,実際に見えている画像にはオレンジ色のカップは1つしかないという複数名詞不一致条件がありました。
このような数が一致しない条件でも,「カップの上に玉ねぎ」とか,「カップの右に鳥」というような位置関係は一致していました。
英文が表している空間的な位置関係は正しいが,名詞の単数・複数に違いがあり,その時に,この「数の違い」に反応して,「あれ?数が違うぞ?」となって反応時間が遅れるかどうかというところがポイントです。オリジナル研究のJiang et al. (2017)では,「位置関係だけに着目して「絵と英文がマッチしているかどうか」を判断するように求められていました。
ところが,私がこの実験をやる前に行ったパイロット調査で,「数が違うときに,合っていると判断したらいいのか,どうしたらいいのか迷った」というコメントが英語母語話者からも日本語話者からも複数聞かれました。指示の曖昧性がある状態で実験をするよりも,思い切って,明示的に,「数が一致しなくても無視して,絵と英文の一致を判断する」としたほうが良いだろうと判断して,私は実験前に,名詞の単複の違いは無視するように参加者に伝えました。
結果として,Jiang et al. (2017)では学習者群で反応時間の遅れが見られなかった(a)の条件で反応時間の遅れが見られたんですよね。ところが,(b)の条件では遅れが見られなかったのです。この結果をどう解釈するのかというのが結構難しくて,最終的に意味的有標性という概念を使いました。これは博論でも使っています。
ところが,査読者(おそらくNan Jiang先生かあるいはあの研究の著者のどなたか)からは,指示を変えたのが結果が変わった大きな要因だ。元の研究と同じ条件でもう一度実験をやり直すべきみたいな感じで言われました。「練習試行で慣れさせれば,明示的な指示を与える必要はない(私たちはそうだった)」みたいな。私としては,でも,母語話者は指示があってもどっちの不一致条件でも遅れているわけで,その指示が母語話者には影響しなくて学習者にだけ影響したのか,どうやって説明するんですかという気持ちでした。さらに,その指示の影響でどちらの条件でも有意差が出たり出なかったりするのならまだしも,片方は有意差があり,片方の条件では出なかったという非対称性についてもなぜそうだったのかの説明が必要になります。
やめないこと
博論を構成する研究は,未出版のものであることというのがまあ約束としてあったのですが,それは,就職して間もないころは忙しいので,すでに出来上がった研究を投稿論文にすることでとりあえずは「食いつなげるように」ということだったわけですが,私はそれすらもできずに,結局この研究を8年間も引っ張ることになってしまいました。情けないなと思う気持ちもある一方で,辞めなかったことだけはポジティブにとらえています。そんだけ時間が経っていたら内容のことも記憶から薄れてしまっていますし,時間とともにモチベーション自体もやっぱり下がってきます。この論文の投稿プロセスについて相談していたGeminiには次のような厳しいことも言われましたしね…苦笑


昔,私の先輩である草薙さんが,
研究者は自分を「書けないタイプ」だとみなしたら終わり。せいぜい「たくさんは書けないタイプなだけ」とか「今はまだ書けないだけ」と思うこと
というアドバイスをしてくれました。たぶん,このブログでも何回か書いたことのある話ですね。
私は就職してからずっと,自分はたくさん論文を書けるタイプではないと思っていました。就職後2年間は本当にそうでしたし,コロナ禍後に心がボロボロになったときも,「今はまだ」と思っていました。でも,とにかく辞めない,書いて投稿することをどんなにペースが遅くてもやり続けようと思ってここまでやってきました。私の場合,研究をデザインして出版までいくのに平均して3-4年はかかっているので,時間はかかりすぎているとは思います。でも,何もやらないよりは100倍ましだと思ってやっています。私は一流の研究者でもないし,たくさん引用されるような論文を書いているわけでもない,人より優れた才能があるわけでもない,平々凡々なただの人ですが,とにかくやめないこと,これだけはこれから何十年も続けたいと思います。
最近,「博士課程で連続的に成長する」というnote記事を読みました。
私はもう「まずは一本だ出す」とかそういう段階は通り過ぎた研究者ですが,「前に進んでいない感覚」は今でも持っています。関連するようなことをnoteの方にも書いています。
前に進んでいる感覚はないけれど,とにかくやり続けて,最後に最終講義(というようなものが未来に存在するかわからないですが)とかで,自分のこれまでの研究人生を振り返ったときに,「まあ,なんかやったっちゃやったわな」と思えたらそれで御の字だなと思います。
おわりに
最後はなんかちょっと論文の紹介からズレてしまいましたが,これからもほそぼそとやっていきます。
なにをゆう たむらゆう。
おしまい。









