草薙さんが最先端いってると思っていたらついにL2研究でもDiffusion modelを取り入れる研究が出てきたか。いやーしかしこれはついていくのしんどいな…

草薙さんが最先端いってると思っていたらついにL2研究でもDiffusion modelを取り入れる研究が出てきたか。いやーしかしこれはついていくのしんどいな…
タイトルの意味は,まずは国内のいわゆる「全国誌」といわれるもの(e.g., 全国英語教育学会のARELE, 外国語教育メディア学会の機関誌)に出して,もしリジェクトされたら国際誌に出すというもの。
この志向がいいのか悪いのかはよくわからないが,ARELEに落ちた論文をLanguage Teaching Researchに載せた先輩がいるとこういう考え方になるのかな。
論文の内容によっては国際誌—といっても幅広いが—の方がマッチするというケースもあるように思う。特に私の(メインの)研究なんかは,国内誌で大きいところに出すのを躊躇するような内容だったりする。心理言語学系のジャーナルは国際誌だと結構あるので。国際誌はコワイから出さないということもあるのかもしれないが,落ちたら落ちたで別のところに出せば良いし,選択肢は1つだけじゃあない。そして,なにより分野が近い人に査読してもらえることの方を重視する。リジェクトされて元気が出るような研究者は—よっぽどのMっ気がない限りは—いないと思うし,誰だってそのときはへこむだろう。しかしながら,論文をpublishし続けている人は,その裏でリジェクトだってもらっていると思う。それでも出し続ける強さがないと—そしてそれは研究者として大事な素質だと思う—,コンスタントに論文を書くのは無理だろう。その点で,「落ちたら国際誌」の志向は相当強い。ただの若気の至りかもしれないが。
この勢いが,あと30年続くかどうか(40あたりで歳下に尻を叩かれたり論文を全然書いてないけど査読するようなオトナになりたくない)。問題はそこ。
なにをゆう たむらゆう
おしまい。
Nagoya.R #15の発表資料をslideshareにアップロードしていたのですが,どうもうまく表示されないので,speakerdeckにもアップロードしました。こちらだと正常に表示されるようです。
教えていただいたlangstat先生ありがとうございました。
なにをゆう たむらゆう
おしまい。

直前のお知らせになってしまいましたが,たくさんの方のご参加をお待ちしております。
参加・発表申し込みはこちらから(当日飛び込み歓迎です)-> https://atnd.org/events/75816
この制度はちゃんと活用されたら素晴らしいなと思う。今後,機会があれば応募してみたいし,うちの分野から優秀な人がこういうポジションに就いて,きちんと計画された大規模なプロジェクト型の教室研究をやってほしいなと思う(研究費も結構もらえるみたいだし「研究室のリーダー」的なものになれるようだ)。ただ,次の条件の③が自分にとっては少し厳しい。これだと,一度常勤なりポスドクなりの立場で研究する期間が修了後または満退後に必要になる。
①博士の学位を取得又は博士課程に標準修業年限以上在学し、所定の単位を修得の上、退学した者(いわゆる「満期退学者」)
②平成29年4月1日現在,40歳未満(ただし、臨床研修を課された医学系分野においては43歳未満)の者
③博士の学位を取得後又は博士課程の満期退学後(社会人学生であった場合は、学位取得前を含む)に、研究機関における研究経験を有する者
情報源: 卓越研究員事業(Leading Initiative for Excellent Young Researchers(LEADER) ):文部科学省
p.s. 白眉をしらまゆとか読んだりしてませんからねッ(汗
届きました。

査読委員(って言わないか)の中に知っている先生方が何人も載っていて驚きました。そして,豪華。この号から外部査読制度を取り入れたとのことで,それが大きいのでしょう。
私の修士論文の研究も載っています。
Tamura, Y. (2015). Reinvestigating consciousness-raising grammar task and noticing. JABAET Journal, 19, 19–47.[abstract]
査読のコメントはとても有益なものが多く,非常に勉強になりました。学会員しか投稿の権限はありませんが,良いジャーナルだと思います(宣伝)。ウェブ上での情報が少なく,いろんな人に認知されにくいというのはありますが,これからそのあたりも今後充実していくことを望みます。
なにをゆう たむらゆう
おしまい。
明日,2月27日に名古屋学院大学で開催される,外国語教育メディア学会中部支部外国語教育基礎研究部会第3回年次例会で発表する際に使用する投影資料をSlideShareにアップロードしました。
※slideshare上でうまくサムネイルが表示されないようですが,全画面表示にする,あるいはファイルをDLしてご覧いただく等で問題が解決すると思われます。ファイル自体は問題ないので。今までとスライドの元のデザイン同じなのになぜこの問題が発生するのかわからず若干不機嫌ではあります。
なお,当日は,結果の部分の図表や引用文献の一覧を印刷した資料を配布する予定です。内容はスライドと重複しますが,紙版の資料も閲覧・ダウンロード可能にしていますので,以下リンクよりどうぞ。
https://drive.google.com/file/d/0BzA9X1kZX185Nk5ONDJ5eUlOLVk/view?usp=sharing
ちなみに,これまで特に指定のない場合に配布資料を配ることはなかった私が配布資料を配るのはこのブログ記事の影響ではありませんw
単純に,結果の図表くらいは配ったほうが良いかもしれないというのは何回か発表を重ねるうちに思ったというのが大きいです。
ある人に,「なめたアブストラクト書きやがったな」と言われてヒィィって感じですが,どうか当日はよろしくお願いいたします。
なにをゆう たむらゆう
おしまい。
2016.03.28追記
slideshareでうまく表示されないようなので,speaker deckにスライドをアップしました。
ちょっとわけあって,欠損値の処理について勉強するソルジャー業務機会がありました。そこで,多重代入法(MI: Multiple Imputation)という方法をRで実行する方法を少しかじったのでメモ代わりに残しておきます。
ちなみに,欠損値の分析をどうするかという話は全部すっ飛ばしますのでそのあたりは下記リンクなどをご参照ください。
多重代入法に関してはこのあたりの資料をどうぞ。
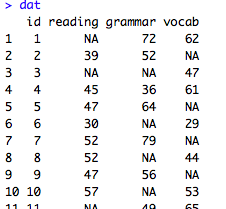
#まずはデータセットの下準備。こんな仮想データだとします。
#id =参与者ID, reading = 読解テストの得点,grammar = 文法テストの得点,vocab = 語彙テストの得点
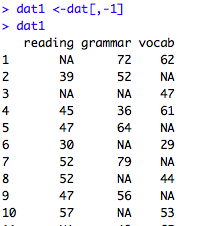
#id列はいらないのでid列を抜いたデータセットを作る
dat1 <-dat[,-1]
#欠損を可視化するにはVIMというパッケージが便利
install.packages(“VIM”)
library(VIM)
#欠損情報を入手
m <-aggr(dat1)
#うまくいくとこんな感じで欠損情報を可視化してくれます
左側が欠損の割合で,右側が欠損のパターン。赤い所が欠損です。
#数値で確認する場合はmの中身を見る
#Multiple Imputation by a bootstrappted EM algorithm (Amelia Package)
#パッケージのインストール
install.packages(“Amelia”)
library(Amelia)
#amelia()関数をまずは使います
#引数は以下のとおり
#x = data.frame
#m = 何個のデータセットを作るかの指定
#dat1.outという変数に,多重代入した結果を入れます
dat1.out <-amelia(x = dat1,m = 5)
#中身はsummaryで確認します
summary(dat1.out)

#補完データの分散共分散行列をみる
dat1.out$covMatrices

#補完データを書き出し
#separate =Fと指定すると,データが1つのファイルに書きだされます
#separate = Tにすると,データセット1つにつき1ファイルで書きだされます
#dat1.ameria.csv, dat1.ameria1.csv, … dat1.ameria5.csvみたいな感じで番号をつけてくれます
#orig.data=Tで,オリジナルのデータを出力する際に含めるかどうかの指定ができます
write.amelia(obj = dat1.out,“dat1.amechan”,separate=T,orig.data = F)
#AmeliaView()を使うと,GUIで操作できます(重いです)
AmeliaView()
#多重代入した結果得られた補完データをまとめる作業をします
#例として重回帰分析をやってみます
#独立変数 = grammar, vocab
#従属変数 = reading
m =5
b.out <-NULL
se.out <-NULL
for(i in 1:m){
ols.out <-lm(reading ~ grammar+vocab,data=dat1.out$imputations[[i]])
b.out <-rbind(b.out, ols.out$coef)
se.out <-rbind(se.out, coef(summary(ols.out))[,2])
}
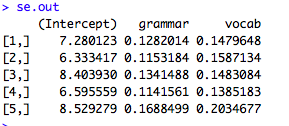
#b.outにはbetaが5つ入っています
b.out
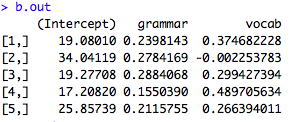
#se.outには標準誤差(SE)が入っています
se.out
#mi.meld()で,5つのbetaとSEをまとめます
combined.results<-mi.meld(q = b.out, se = se.out)
combined.results
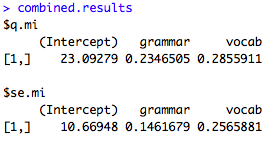
SEがちょっと広めですかね
というわけで,まとめる段階が手動で関数書いていますが,それ以外は割りと簡単にできます。ファイルの書き出しなんかもできますし。
補足
miceパッケージを使うともっと簡単に多重代入->分析->統合ができるようです。
install.packages(“mice”)
library(mice)
imp_data<-mice(dat1,m = 5)
fit <-with(imp_data,lm(reading ~ grammar + vocab))
summary(pool(fit))

まぁまぁ結果は近い?
なんかmiceパッケージの方が使い勝手が良さそうですね(アレレ
ちょっとまた時間があったらもう少し勉強してみたいと思います。
今日はこのへんで。
なにをゆう たむらゆう
おしまい。
先日ついにtidyrパッケージで縦横変換をやってみた。今までずっと覚えなきゃなと思ってて結局億劫でやってなかったんだけれど手伝いで仕方なく。
データハンドリングで,横に広がる(列数の多い)wide-formatのdataを分析に便利なlong-formatに変換するというのは,分析をやるまえのデータ整形の過程で必ず通らなければならない道。Excel上で地道にやるのもあるにはあるだろうけど,Rのtidyrを使えばすぐできるというお話。これ系の話はググればネット上にゴロゴロ記事が転がっている。なので,今回は具体的に外国語教育研究系のデータ分析ではどんなときに役に立つかなーという話です。特に無駄に変数が多い時なんかは結構役に立つと思います。

sample data
適当にこんな感じでデータが入っているとします(数値は乱数)。事前・事後・遅延事後のテストがあって,それぞれで流暢さ(fluency),正確さ(accuracy),複雑さ(complexity)の指標があるみたいな。1列目には被験者番号があって,それぞれの列名は”test.measure”という感じでドット区切りにしてあります。で,これを,「事前・事後・遅延事後」の3つのカテゴリカル変数からなる”test”列と,3つの指標(CAF)の”measure”列の2列に分解しましょうという話し。
R上に上のようなデータを読み込みます。

read.table関数で読み込んだ場合(※MacなのでちょっとWindowsと違います)
まずはパッケージの準備
install.packages(“tidyr”) #パッケージのインストール
library(tidyr) #tidyrパッケージの呼び出し
datに入っているデータフレームをまずは,変数名の列(variable)とその値(value)の列に集約します。key=変数名の列,value=値の列という引数指定です。
#%>%はパイプ演算子。以下の関数で扱うデータフレームを指定するということです
dat %>%
#-subjectでsubjectの列を除外。変換したdataをdat2に入れる
gather(key = variable,value = value,-subject) -> dat2
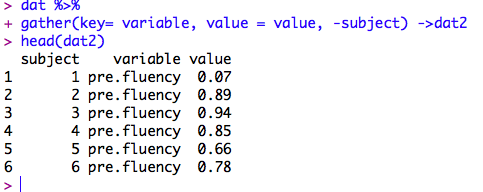
long formatのデータに変換されました
これで変数名を1列に集約できました。ただし,この列にはpre, post, delayedというテスト実施時期の情報と,fluency, accuracy, complexityという指標の情報が混ざってしまっています。これを,2列に分けます。
dat2 %>%
#colで分けたい列名,intoで分けた後の列名を指定。sepでセパレータを指定しますが,デフォルトはあらゆる非アルファベットになっているので,ドットなら指定しなくても大丈夫
separate(col = variable, into = c(‘test’, ‘measure’)) -> dat 3
さて,dat3の中身を確認してみると…

long formatのデータに変換されました
おおおおー!!!!!
というわけで,横に変数がたくさんある場合もこのtidyrのgatherとseparateを使えば簡単にlong型に変換できそうです。
参考サイト:http://meme.biology.tohoku.ac.jp/students/iwasaki/rstats/tidyr.html
なにをゆう たむらゆう
おしまい。
ストレスが溜まっているのかなんなのか帰り道にセブン-イレブンでチーズとワインを買って飲むとかいう珍しいことをしているという言い訳を最初に書いておこうと思います。それから,自戒もたっぷり込めていることも申し添えておきたいと思います。
データ分析の方法の相談についてです。色んな所で起こっていることだと思うし色んな人がきっと同じようなことを考えているだろうと思います。一言でいうと,データを取る前に相談してみましょうということです。データを取ったあとに,「このデータってどうやって分析すればいいですか?」っていう質問は結構つらいところがあったりします(恐れ多くもなぜだかこういう質問をされる立場に私もなってしまいました)。なぜなら,本当にその質問者の方が調べたいこと,明らかにしたいことが,そのデータ収集方法で明らかにすることができるのかちょっと怪しかったりすることがあるからです。
そういう状況にならないために重要なことは,研究課題を見つけて,それを具体的な実験計画なりに落としこむ際に,その先のことまでちょっと考えてからデータ収集をしてみることだと思います。つまり,
こういう方法を使うと,こういうデータを収集することができる。それをこういう分析にかければ,こういう結果が得られるはず。もしこういう結果が得られた場合,それはこういうことを意味していると解釈できるだろう。
みたいなことを考えてから実験を組んで,データを取っていただきたいなということです。そうすれば,データを取ってからどうしたらいいかという質問が来ることはなくなるからです。上述の事でイマイチ自分がうまく説明できないとなったら,その時点で相談をすればよいと思います。そうすれば,実はその方法で得られたデータで,質問者の方の主張をするのはちょっと違うので,こういうデータ収集をしないといけませんよ,なんてアドバイスができたりするかもしれないからです。これって仮説検証型の研究でも探索的な研究でも同じだと思います。たとえ探索的な研究だったとしても,得られた結果に対してなんらかの解釈を加える必要はあるはずですから。研究課題がwh疑問文で始まる形であったとしても,結果に対しては,きっとこういう理由でこうだったのだろうということを言えなければいけないわけですし。
データをとって,分析をしてみて,これであってるのか不安だから相談してみようということもあるのかもしれませんが,それって別にデータ取る前にもできることなんですよね。
こういう研究課題をもっていて,これを明らかにするためにこういう分析をしてこういう結果が得られたらこういう解釈ができると思うのですが,これで合ってますか?
ってデータ取る前に相談すればすむと思うのです。なのにどうして,「データを取ったあとにこれってどうやって分析すればいいんですか?」ってなってしまうのでしょう。
これはあくまで持論なのですが,研究って,研究のデザインとか実験計画ですべて決まると私は思っています。面白いなと思う研究はやっぱりデザインがしっかりしていて,分析の結果から得られたことの解釈がとってもシンプル(注1)なんです(そういう研究が良い研究だと思う私からすると,discussionを長々と書いている論文やそれが良しとされる風潮,また「discussionが短い」みたいなコメントってなんだかなと思ったりします)。それって,デザインを練る段階で色んなことを考えているからなんですよね。研究の計画を立てる段階で,データの分析方法まで明確にイメージできない場合は,データ収集に入るべきではないと私は考えています。私の場合は基本的に,ある研究で行われることを考えることは,R上で分析を行う際のデータセットの形をイメージすることとほぼ同義です。変数のデータフレームがイメージできていて,それをどうやって分析すれば何をどうしていることになるのか,こういう結果になったらそれはどう解釈するのか,また別の結果がでたらそれをどう解釈するのかまで考えられて初めて研究のデータ収集ができるのではないでしょうか。
こういった考えが当たり前になれば「統計屋さん」(私は違いますけど)とか言われる人たちもずいぶん楽になるのではないかなと思っています。
なにをゆう たむらゆう
おしまい。
*注1: だからといって,t検定一発で明らかになることってそんなにはないとは思います。少なくとも今なら昔はt検定一発だったこともGLMMするでしょう。例えば正答率の平均値をt検定というのはもはや時代遅れになりつつあるわけですし。